Operating system - Segmentation
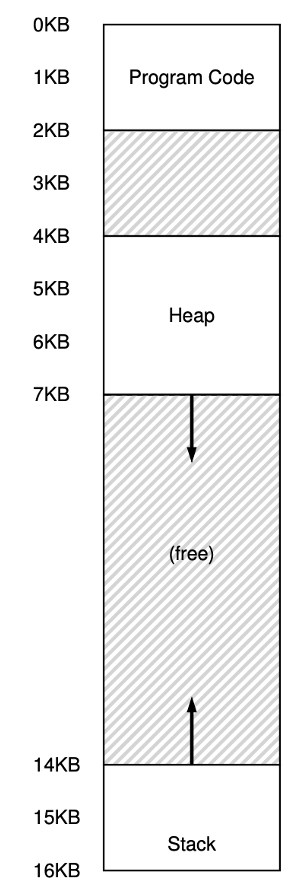
지금 우리가 배운건 베이스와 바운드 레지스터를 이용해 주소 공간 전체를 메모리에 탑재한다. 이 방식은 스택과 힙 사이의 공간이 사용되지 않더라도 물리 메모리를 차지하고 있다. 그렇기 때문에 메모리 낭비 (wasteful) 가 심하다. 그리고 주소 공간이 물리 메모리보다 클 때 실행이 메우 어렵기 때문에 베이스 바운드 방식은 유연성이 없다 (not as flexible).
◼︎ 세그멘테이션: 베이스/바운드의 일반화 (Generalized Base/Bound)
위의 문제를 해결하기 위한 방법은 segmentation이다. 이 방식은 하나의 베이스와 바운드 쌍이 존재하는 것이 아닌 주소 공간의 논리적인 세그멘트마다 베이스와 바운드 쌍이 존재하는 것이다(have a base and bounds pair per logical segment of the address space).
- Segment: 특정 길이를 가지는 연속적인 주소 공간(a contiguous portion of the address space of a particular length)
- 코드
- 스택
- 힙
각 segment를 물리 메모리의 다른 위치에 배치할 수 있고 사용되지 않는 가상 주소 공간이 물리 메모리를 차지하는 것을 방지할 수 있다.
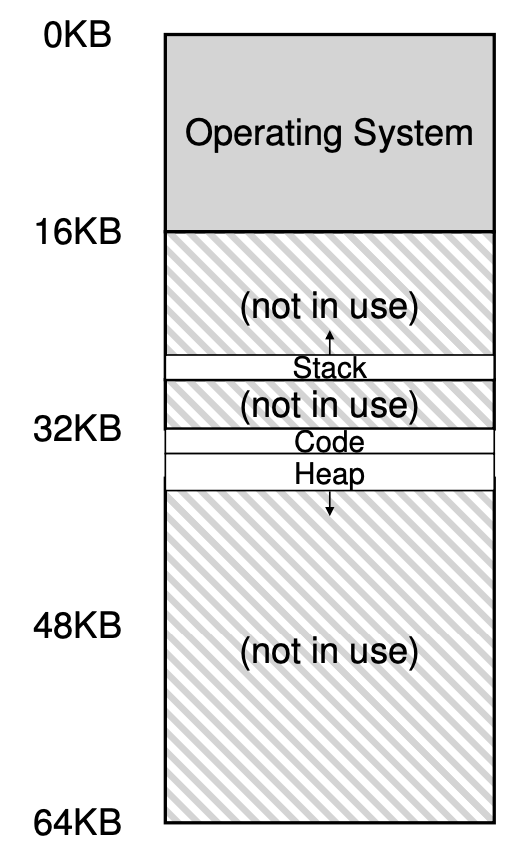
| Segement | Base | Size |
|---|---|---|
| 코드 | 32KB | 2KB |
| 힙 | 34KB | 2KB |
| 스택 | 28KB | 2KB |
Offset은 Address - logical bass이다. 그래서 저장되는 물리 주소를 알고 싶으면 Offset + memory bass를 더하면 되는 것이다. 예시를 들어보자 가상 주소가 100일 때는 code segment에 속하고 segment의 offset은 100이 되고 물리 주소는 32B+100이 된다. 하지만 가상 주소가 4200인 heap을 보자. 이거는 아무생각 없이 34B+4200을 하게되면 틀리게 된다. 4200은 offset이 아니기 때문이다. 제대로 구하려면 4200 - 4KB = offset이 되는 것이다. 그래서 주소가 4200인 heap은 34KB + 4200 - 4KB = 30KB + 4200이 되는 것이다.
이렇게 구하면 될 것 같지만 만약 힙이 7KB같은 잘못된 주소로 접근하게 되면 어떻게 되는 것일까? 이러면 주소가 벗어났다는 것을 하드웨어가 감지하고 운영체제에서 트랩을 발생시켜 프로세스를 종료할 것이다. 이것을 segment violation 또는 segment fault라고 한다.
◼︎ Segment 종류의 파악
방금 우리는 사실상 그 주소가 어떤 종류의 segment를 가지는지 알고 주소를 찾았다. 그런데 실제로는 미리 알 수 없다. 그래서 이것을 구별해 줘야 한다.
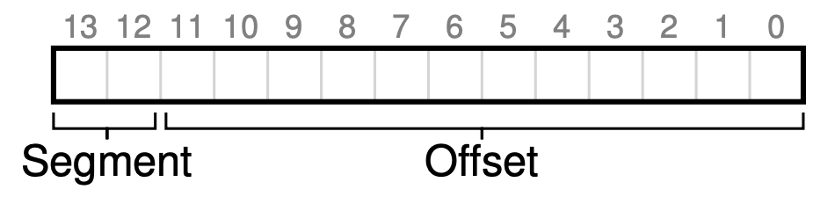
이렇게 앞에 필요한 만큼 앞의 비트를 할당하여 segment의 종류에 대한 정보를 저장한다. 위의 segment를 예시로 들면 3개의 type이 존재하니 2bit가 필요하고 00은 코드, 01은 힙, 10은 스택으로 할당해주면 되는 것이다.
◼︎ 스택
스택의 경우에는 다른 segment와 달리 반대방향(주소가 작아지는 방향)으로 확장된다는 것이다. 그렇기 때문에 다른 방식의 변환이 필요하다. 우선 어느 방향으로 확장되는지 알게하는 하드웨어가 필요하다. 그래서 예로 1을 주소가 커지는 방향, 0을 주소가 작아지는 방향과 같이 설정을 해서 구분할 수 있도록 해야한다. 그리고 (-)연산이기 때문에 다른 방식의 변환법이 필요하다.
◼︎ 공유 지원(Support for sharing)
Segmentation이 발전하면서 하드웨어 지원을 통해 메모리를 절약하는 방법인 segment를 공유하는 것을 도입하였다. 그래서 하드웨어에 protection bit를 추가로 만들어 줘야 한다. Segment를 읽기 전용으로 설정하면 주소 공간의 독립성을 유지하면서도 주소 공간의 일부를 공유할 수 있다.

◼︎ 소단위 대단위 segmentation
지금까지 다룬 코드, 스택, 힙 등은 대단위(coarse-grained) segmentation이다. 왜냐하면 주소 공간을 큰 단위의 공간으로 분할하기 때문이다. 그래서 작은 공간으로 분할하는 segmentation은 소단위(fine-grained)라고 한다.
◼︎ 운영체제의 지원
Segment는 많은 문제점을 제기한다. 그 중 우리가 생각해볼 것은 미사용된 물리 메모리 공간을 어떻게 관리할 것이냐에 대한 문제이다. 이렇게 되면 총 메모리 공간이 요청한 메모리 공간보다 크지만, 남아있는 공간이 연속적(continous)이지 않은 상황이 발생한다. 그러면 잘라서 넣어야 하는 걸까? 이렇게 미사용 공간이 부분 부분에 있으면 좋지 않다. 이 문제르 외부 단편화(external fragmentation)이라고 부른다. 그래서 이 문제를 물리 메모리 압축을 통해 해결한다. 그림과 같이 하나로 할당시키고 나머지는 미사용으로 둔다.
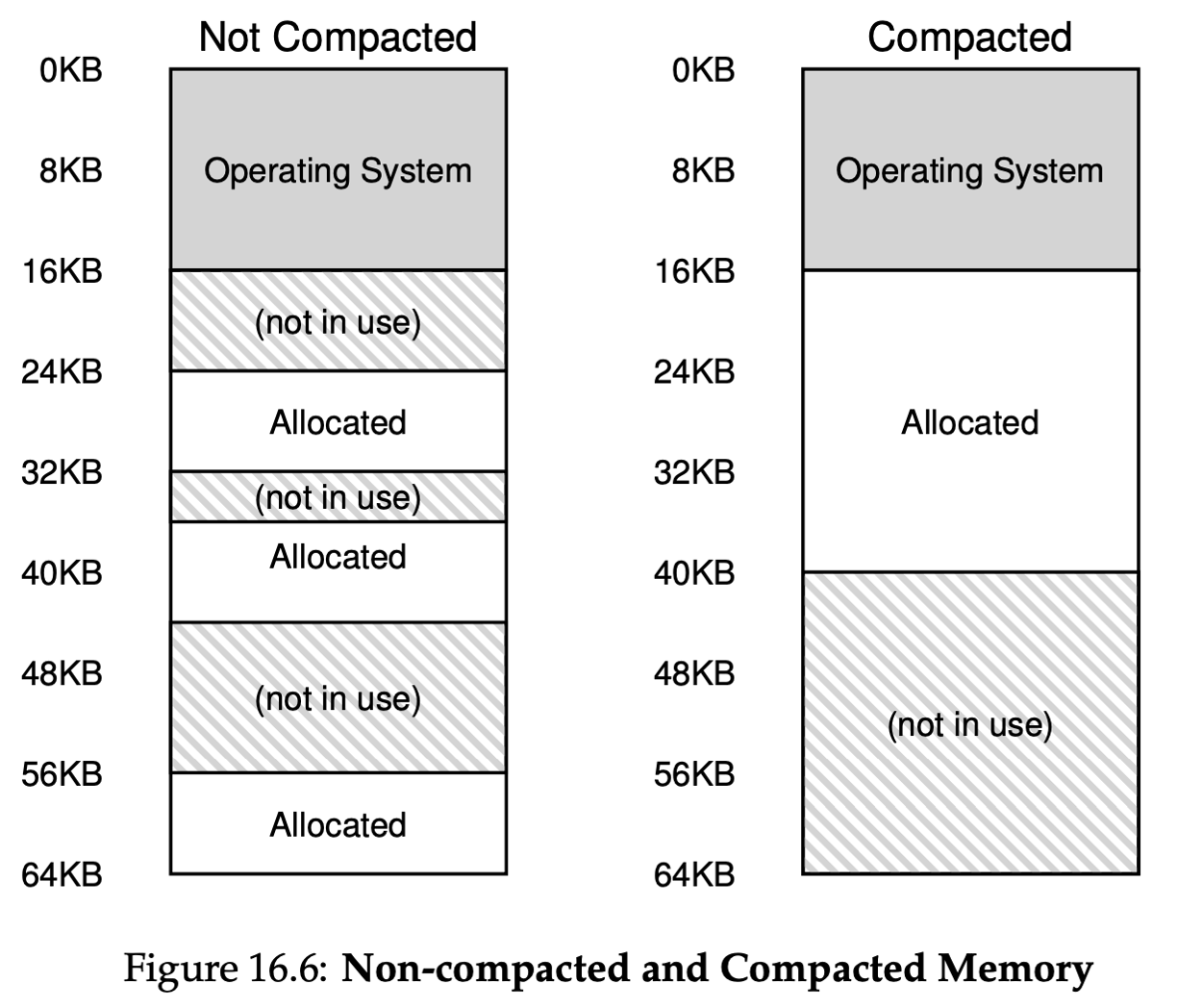
하지만 이렇게 압축에는 segment 복사 과정이 필요하고 이것은 메모리에 부하가 큰 연산이고 많은 시간을 사용하기 때문에 비용이 크다. 그래서 빈 공간 리스트를 관리하는 알고리즘을 사용하여 해결한다. Best Fit, Worst Fit, First Fit, 그리고 Buddy alorithm 등 여러 알고리즘이 있다. 아무리 좋은 알고리즘이어도 외부 단편화는 피할 수 없지만 이를 최대한 줄이는 것이 목표이다.
◼︎ 빈 공간 관리 (Free space management)

이렇게 메모리는 어느 경우에든 외부 단편화(external fragmentation)이 생길 수 밖에 없다. 위의 메모리에 15바이트의 요청이 들어왔으면 총 20바이트의 빈 공간이 있음에도 불구하고 실패하게 된다. 그래서 이를 해결하는 여러 방법에 대해 다뤄보려 한다.
저수준 기법(Low level mechanism)
우선 분할(splitting)과 병합(coalescing)의 기초에 대해 다룰 것이다. 그리고 할당된 영역의 크기를 빠르고 쉽게 파악하는 방법에 대해 알아볼 것이다. 마지막으로는 빈 공간과 사용 중인 공간을 추적하기 위해 빈 공간에 간단한 리스트를 구현하는 방법에 대해 다룰 것이다.
-
분할(splitting)과 병합(coalescing)
위의 예시 메모리를 아래의 빈 공간 리스트 처럼 나타낼 것이다.
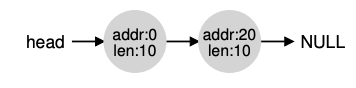
만약 10바이트를 초과하는 요청이 들어오면 NULL을 반환하게 된다. 10바이트가 들어오면 둘 중 하나의 빈 곳에 들어가게 된다. 만약 10바이트 보다 작은요청이 들어오면 어떻게 될까? 1바이트의 요청이 들어왔다고 하면 이때는 분할(splitting)을 하게 된다. 요청을 할 수 있는 빈 청크를 찾아 이를 분할하고 첫 번째 청크는 호출자에 반환되고 두 번째 청크는 리스트에 남게 된다. malloc()을 요청했으면 아래의 상황에서는 20(1바이트가 할당된 영역의 address)을 반환하게 된다.
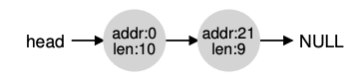
분할에는 병합(coalescing)이 동반되게 된다. free(10)을 호출 했을 때의 상황에 대해 보겠다. 그러면 아래의 힙 리스트 처럼 길이가 10바이트인 청크 3개로 나누어지게 된다. 하지만 이때는 20바이트를 요청하게 되면 NULL이 반환되게 된다. 그래서 이를 병합해줘야 하는 것이다. 해체되는 청크의 주소와 바로 인접한 빈 청크의 주소를 살펴봐서 free가 된 공간이 왼쪽의 청크와 붙어있으면 하나의 청크로 병합하면 된다. 그러면 최종 리스트는 다음과 같이 된다.

- 할당된 공간의 크기 파악
free(void *ptr) 인터페이스는 크기를 매개변수로 받지 않는다. 그래서 malloc 라이브러리는 free되는 메모리 여역의 크기를 파악해야한다. 이것을 해결하기 위해 정보를 헤더(header)에 저장한다. 헤더는 메모리에 유지되고 free된 chunk직전에 위치한다.
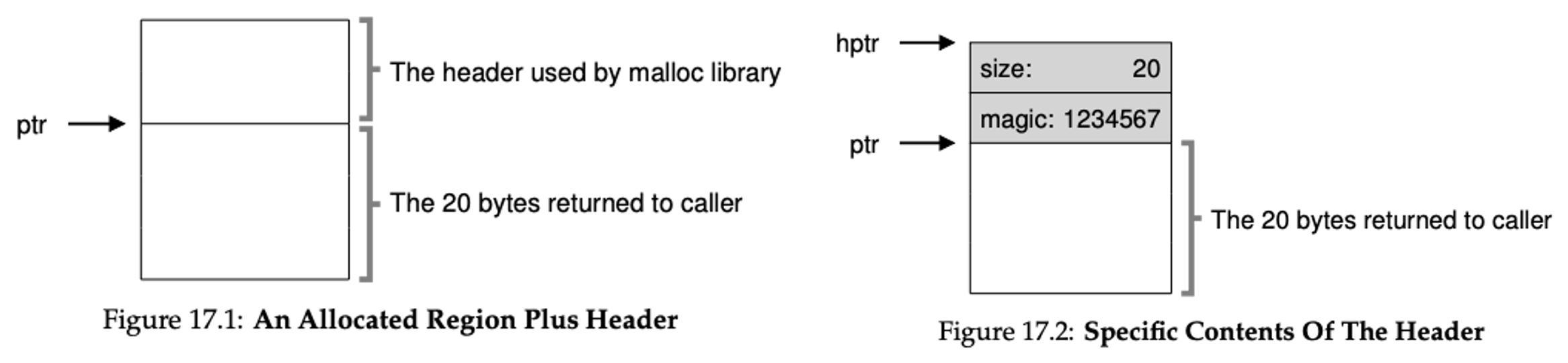
여기에서 magic number는 파일형식이라고 생각하면 된다. Header에 저장되는 고유의 시그니처이다. 이는 헤더를 가르키는 포인터를 얻어내면 이것이 매직 넘버의 기대값과 같은지 일치하는지 비교하는 안정성 검사(sanity check)에 사용된다. 그래서 사용자가 N바이트의 메모리 청크를 요구하면 N보다 큰 빈 청크를 찾는 것이 아닌 “N+header_size”보다 큰 빈 청크를 찾는다.
- 빈 공간 리스트 내장
좀 더 복잡한 경우의 예시를 봐보자. 4096KB 크기의 힙이있고 시작주소는 16KB 그리고 헤더의 크기가 8byte를 가정하자. 크기가 100byte의 요청이 계속 왔다고 가정해보자.
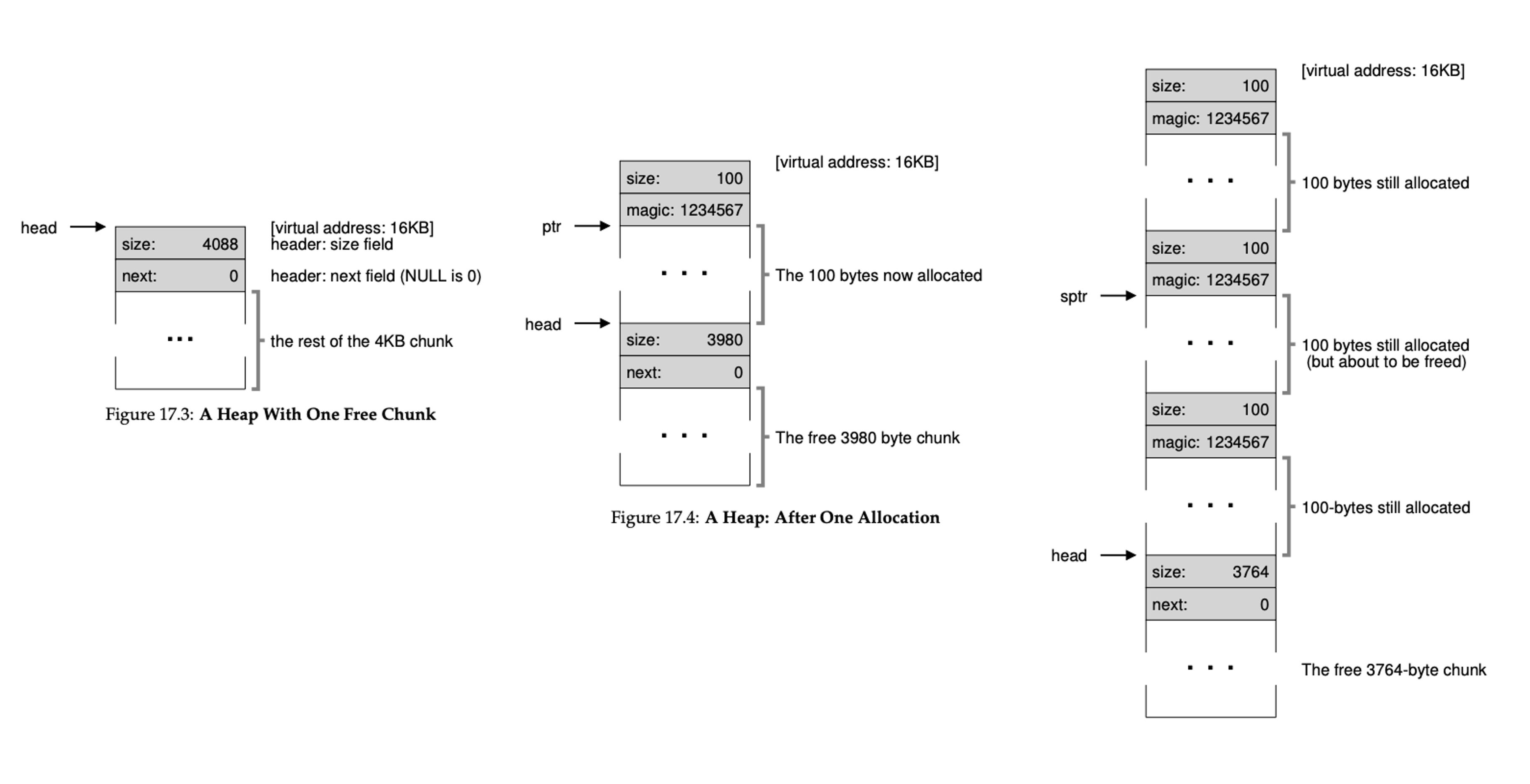
100byte의 요청이 오면 헤더를 포함한 108byte를 할당하고 마지막에는 할당 영역을 가르키는 포인터(ptr)을 반환하게 된다. 여기에 free(16500)을 호출했다고 해보자. 16500 = 시작주소(16384) + 이전 메모리 청크 크기(108) + 헤더 크기 (8)을 해서 나온 값이다. 이 값은 sptr위치이다.
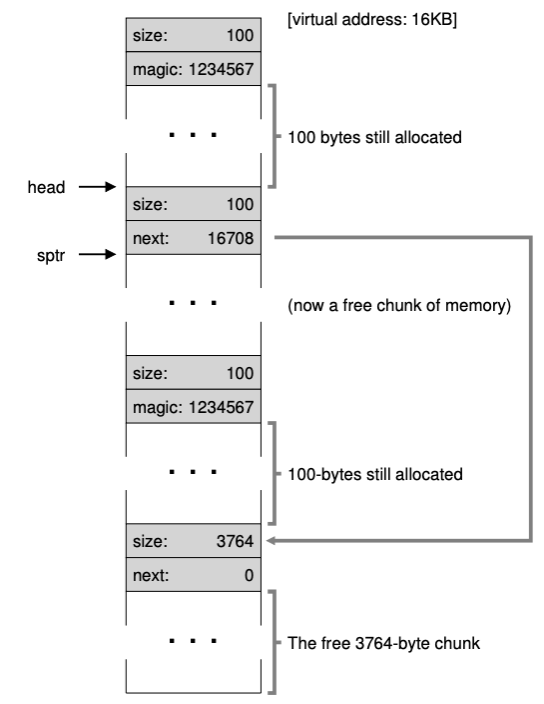
next 16708은 다음 비어있는 공간의 주소를 나타내게 된다. 그런데 이렇게 되면 단편화가 발생하게 된다. 그래서 병합을 해야하는 것이다. 근데 병합을 하기 전에 힙 공간이 이렇게 부족할 때는 어떻게 해야할까? 제일 쉬운 방법은 NULL을 반환하는 것이다.
-
기본 전략
그래서 빈 공간 할당을 위한 기본적인 전략에 대해 살펴보겠다.
- Best Fit <>
빈 공간 리스트를 검색해서 요청한 크기와 같거나 더 큰 메모리 청크를 찾은 후 그 청크들 중 가장 작은 크기의 청크를 반환하는 것이다. 그래서 최소 적합이라고 불리기도 한다. 이는 리스트를 한번만 순회하면 반환할 정확한 블럭을 찾을 수 있다. 그렇기 때문에 항상 전체를 검색하게 되고 성능 저하가 일어난다. - Worst Fit
Best fit과 정반대의 방식이다. 가장 큰 빈 청크에 요청된 크기만큼 반환하고 빈 공간 리스트를 계속 유지하는 방식이다. 이 방식도 전체를 검색하게 된다. - First Fit
요청보다 큰 첫 블럭을 찾아서 요청만큼 반환하는 것이다. 이 것의 장점은 속도가 빠르다는 것이다. 전체를 검색하지 않게된다. 하지만 이는 크기가 작은 빈 공간 리스트를 많이 생성하게 된다는 단점이 있다. Address-based ordering을 통해 병합을 쉽게 하고 단편화를 감소시킨다. - Next Fit
마지막으로 찾았던 원소를 가리키는 추가의 포인터를 유지하는 방법으로 빈 공간 탐색을 리스트 전체에 균등하게 분산시킨다. 단편화가 생기는 것을 방지하고 최초 적합과 비슷한 성능을 가진다.
- Best Fit <>
-
다른 전략
- 개별 리스트
자주 요청하는 크기가 있을 때 그 크기의 객체를 관리하기 위한 별도의 리스트를 유지하는 방식이다. - 버디 할당
메모리 요청이 발생하면 요청을 충족하기에 충분한 공간이 발견될 때 까지 빈 공간을 2개로 계속 분할해 가장 작은 공간이 발견되면 요청된 블럭을을 사용자에게 반환하는 방법이다. 그런데 이는 내부 단편화의 문제가 생기게 된다.
- 개별 리스트