Operating system - Translation Lookaside Buffer
앞에서 말했듯 paging은 상당한 성능 저하를 가져올 수도 있다. 모든 load/store 명령어 실행이 계속 반복해서 일어나는 것이다. 그래서 이 주소 변환 속도를 향상시키기 위한 방법을 도입하게 된다. 이는 Translatiion-Lookaside Buffer(TLB)라고 부르는 것이다. TLB는 MMU의 일부이다. 즉, 하드웨어적인 캐시라는 것이다. 그래서 address-translation cache라고 하기도 한다. 하드웨어는 먼저 TLB에 원하는 변환 정보가 있는지 확인하고 만약 있으면 변환을 빠르게 수행할 수 있게 된다.
◼︎ TLB의 기본 알고리즘
우선 가상 주소에서 VPN을 추출한 후 해당 VPN을 TLB에서 검사하게 되는데 만약 존재하면 TLB hit라고 하고 여기서 바로 PFN을 추출할 수 있게 된다. 이 정보를 가상 주소의 offset과 합쳐 물리 주소(PA)를 구성하여 메모리에 접근 할 수 있다. 그렇지 않을 때는 TLB miss라고 한다. 이때는 TLB에 이 정보를 페이지 테이블에서 찾아 갱신하게된다. 그래서 TLB hit가 일어나면 캐시에서 히트되어 빠르게 paging이 가능하고 아닐때는 paging 비용이 커지게 된다.
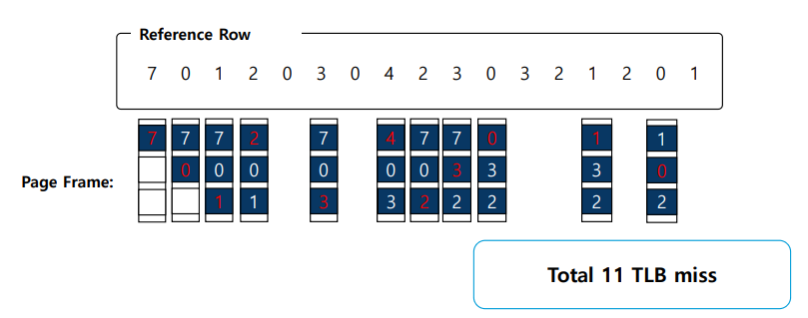
◼︎ TLB 예시
좀더 정확한 과정을 예시를 통해 알아보겠다.

이렇게 16개의 page가 있고 각 page의 크기는 16byte를 가진다고하고 그 안에 4비트의 오프셋이 있다고 하자. 그러면 배열을 순서대로 접근을 할 것이다. 우선 TLB가 완전히 초기화되어 있다고 하면 a[0]에 접근 할 때 VPN06에 대한 정보가 없으므로 TLB miss가 일어나게 되고 TLB를 갱신하게된다. a[1]을 읽을 때는 TLB에 정보가 있어서 TLB hit가 일어나게 되어 시간이 줄어들게 된다. a[2]도 TLB hit이고 a[3]는 miss 다시 a[4]는 hit 이런식으로 반복하게 된다. 즉, a[0], a[3]. a[7]는 miss이고 나머지는 hit로 비율이 70%이다. 그리고 이로 인해 알 수 있는 것은 page의 크기가 클 수록 spatial locality로 인해 성능을 개선할 수 있다. 그리고 프로그램이 루프를 종료하고 난 후에도 TLB 배열을 사용하면 성능은 더 좋을 것이다. 이는 temporal locality로 인해 TLB의 hit율이 좋아진다. 한번 참조된 메모리 영역이 짧은 시간 내에 재 참조되는 현상을 말한다.
◼︎ TLB miss의 처리
TLB miss를 처리하는 방법으로는 2가지가 있다.
- 하드웨어: 페이지 테이블에 대한 명확한 정보와 메모리 상 위치와 형식을 파악하고 있어 miss 발생시 페이지 테이블에서 원하는 PTE를 찾고 TLB를 갱신하고 다시 명령어를 재실행 한다. -> CISC
- OS: TLB miss가 생기면 예외 시그널을 발생시키고 커널 모드로 변경하여 trap handler를 실행하여 변환 정보를 찾고 TLB를 갱신한후 리턴한다. 이는 system call의 trap handler와는 차이가 있으며 miss가 무한 반복 되지 않게 주의해야 한다. -> RISC
◼︎ TLB의 구성
TLB는 32, 64, 또는 128의 entry를 가지며 fully associative한 방식으로 설계 된다. 이 뜻은 정보는 TLB 어디든 위치할 수 있고 검색때 TLB 전체에서 병렬적으로 수행된다는 것이다. 그래서 TLB는 다음과 같이 구성되어 있다.
VPN | PFN | other bits
other bits에는 address-space identifier, dirty bit 등이 있다.
◼︎ TLB의 문제
TLB에 있는 logical address와 physical address간의 translation 정보는 그것을 탑재시킨 프로세스에서만 유효하다. 즉, 다른 프로세스에서는 의미가 없다는 뜻이다. 왜냐하면 다른 프로세스에서 같은 VPN을 가지면 전혀 매칭이 안되고 TBL에는 두개의 같은 VPN이 들어가야하기 때문이다. 그래서 이를 address space identifier(ASID)를 이용하여 해결하게 된다. 이는 PID와 비슷한 역할을 한다. 하지만 ASID가 좀 더 작은 비트를 사용한다.

이제 왼쪽과 같이 ASID를 이용하여 프로세스가 달라질때의 문제를 해결할 수 있게 되고 이로 인해 VPN은 다르지만 PFN이 같을 때도 이용하여 물리 메모리를 공유해 물리 메모리 사용량을 줄일 수 있다.
◼︎ TLB의 교체 정책
모든 캐시가 그렇듯이 TLB에서도 cache replacement의 policy가 중요하다. 그래서 LRU(least-recently-used) 방식을 잘 사용하고 random 정책도 사용한다.