Operating system - I/O Devices
영속성을 설명하기에 앞서 입력/출력 장치의 개념을 소개할 것이다. I/O device는 컴퓨터 시스템을 유용하기 쓰기 위해서는 필요하다. 그러면 시스템에과 I/O를 어떻게 합쳐야 할까?
◼︎ 시스템 구조
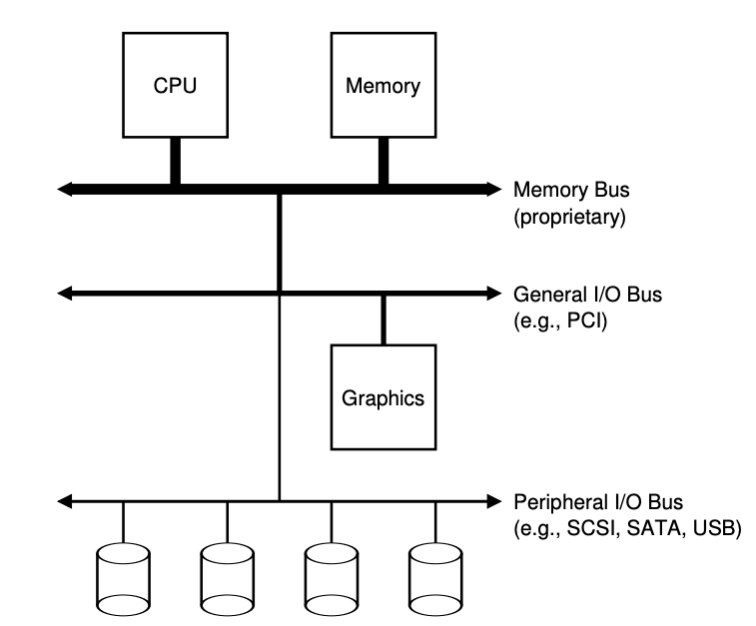
이 구조 그림을 보면 CPU와 main memory는 memory bus와 연결되어 있다. 그 아래로 몇 가지 장치들이 general I/O bus에 연결되어 있다. 현대에는 PCI 방식을 사용하고 그래픽과 같은 고성능 I/O장치가 여기에 연결된다. 마지막으로 맨 아래에 SCSI, SATA, USB 와 같은 peripheral I/O bus가 있다. 이 버스들을 통해 디스크나 마우스와 같은 느린 장치가 연결된다. 이렇게 계층적인 구조를 가지는 이유는 물리학적 이유와 비용 때문이다. 버스가 고속화 되려면 짧아져야하지만 그러면 여러 장치를 수용할 수 없다. 그리고 고속의 성능을 내는 버스를 만드는 기술은 비싸서 고성능 장치들을 CPU와 가깝게 배치되고 느린 장치를 멀리 배치하였다.
◼︎ A canonical device(표준 장치)

위는 표준 장치의 구조이다. 크게 두 개의 중요한 요소로 나눠진다. 우선 시스템의 다른 구성 요소에게 제공하는 하드웨어 인터페이스이다. 소프트웨어가 인터페이스가 있듯 하드웨어도 인터페이스를 제공하여 제어할 수 있도록 한다. 그리고 두 번째 요소로는 내부 구조가 있다. 보통 시스템에게 제공하는 장치에 대한 추상화를 정의하는 책임을 갖고 있다.
◼︎ A canonical protocol(표준 방식)
위에서 보았듯 interfacesms status register, command register, data register로 이루어져있다. Status register는 현재 상태를 읽을 수 있으며 command register는 장치가 특정 동작을 수행하도록 요청할 때 사용하고 data register는 장치에 데이터를 보내거나 받을 때 사용하단. 이 register들을 통해 읽거나 쓰고 이거로 운영체제는 장치의 동작을 제어한다.
1
2
3
4
while (STATUS == BUSY);
DATA
COMMAND
while (STATUS == BUSY);
운영체제와 장치 간에는 위의 4가지 단계를 통해 상호동작을 한다. 이 동작을 장치에 대해 polling한다고 한다.
- OS는 장치의 STATUS 레지스터를 반복적으로 확인해서 BUSY가 아닐 때를 기다린다
- 일부 데이터를 장치의 DATA 레지스터에 보낸다
- 장치의 COMMAND 레지스터에 명령어를 씁니다. 그리고 장치를 해당 명령어로 시작한다
- 장치가 동작 중이므로 끝날 때까지 기다힌다
◼︎ Interupt를 통해 CPU overhead 개선
앞에서 우리는 interrupt handler를 통해 CPU를 다른 프로세스에 양도하는 것을 봤었다. 그래서 사용률을 높이기 위한 방법으로는 CPU와 I/O를 중첩시키는 방법이 있다.

p는 polling이다. 프로세스를 중첩시키지 못할때는 이렇게 해결을 한다. 하지만 프로세스를 동시에 여러개를 사용할 수 있다면 더 효율적이 될 것이다. 다음의 예시가 그것이다.

그런데 항상 interrupt가 제일 좋지는 않다. 매우 빠른 장치면 오히려 polling을 하는 것이 좋다. 왜냐하면 문맥교환을 하는것 자체는 매우 cost가 크기 때문이다. 그래서 빠른 장치면 polling이 좋고 느린 장치는 interrupt가 좋다. 그래서 이를 합치는 하이브리드 방식도 있다. 짧은 시간 동안 polling을 하다가 처리가 완료되지 않으면 interrupt를 하는 것이다. 이렇게 하면 양쪽의 장점만 취할 수 있다.
네트워크에서는 interrupt를 사용하지 않는다. 왜냐하면 대량으로 도착하는 패킷이 있으면 각 패킷마다 인터럽트가 발생되고 이 경우 interrupt만 반복하다가 프로세스 요청을 처리할 수 없게되는 무한반복(livelock)에 빠질 수 있다. 이게 바로 DDOS의 원리다.
Interrupt 기반의 최적화 기법으로는 병합(coalescing)이 있다. 여러번의 interrupt를 하는 것이 아닌 단 한번의 interrupt를 해서 overhead를 줄일 수 있게 된다.
◼︎ DMA
I/O를 사용하여 많은 양의 데이터를 장치에 전송할 때 CPU는 사소한 작업으로 인해 시간을 낭비할 때가 있다. 프로세스 1이 수행되다가 데이터를 디스크에 쓰는 작업을 하는 상황을 예시로 들어보자. 데이터를 쓰기 위해서는 I/O를 사용하여 메모리에서 장치로 데이터를 한 번에 한 개씩 복사하게 된다.

위의 c가 복사를 하는 작업이다. 프로세스 1을 sleep시켰다가 다른 프로세스를 실행하게 되는 건데 이는 CPU를 낭비하는 것이다. 그래서 이를 Direct Memory Access(DMA)를 통해 해결하게 된다. DMA는 CPU의 개입 없이 장치와 메모리 사이의 전송을 조율할 수 있는 장치이다. 그래서 DMA를 이용한 결과는 다음과 같다.
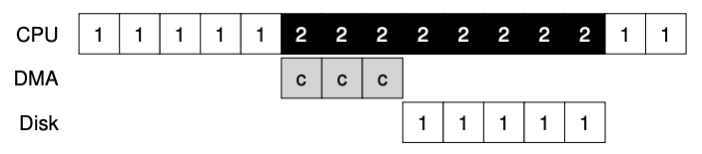
이렇게 하여 더 많은 CPU를 효율적으로 사용할 수 있게 된다.
◼︎ Methods of device interaction
그럼 대체 OS와 장치는 어떻게 소통하는 것일까? 첫 번째 방법으로는 명시적으로 I/O명령을 사용하는 방법이다. privileged 명령어를 통해 장치와 통신하는 것이다. 두 번째 방법으로는 memory mapping이 있다. 하드웨어에서 장치의 레지스터들이 마치 메모리 상에 존재하는 것 처럼 만드는 것이다.
◼︎ Fitting Into The OS: The Device Driver
마지막으로 장치들의 인터페이스를 하나의 OS에서 사용할 수 있도록 하는 방법이다. 이를 가능하게 해주는 소프트웨어를 device driver라고 한다. Linux 코드의 70%가 device driver라고 한다.
◼︎ IDE disk driver
IDE disk는 4가지인 control, command, status, error를 통해 구성되어 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
Control Register:
Address 0x3F6 = 0x08 (0000 1RE0): R=reset,
E=0 means "enable interrupt"
Command Block Registers:
Address 0x1F0 = Data Port
Address 0x1F1 = Error
Address 0x1F2 = Sector Count
Address 0x1F3 = LBA low byte
Address 0x1F4 = LBA mid byte
Address 0x1F5 = LBA hi byte
Address 0x1F6 = 1B1D TOP4LBA: B=LBA, D=drive
Address 0x1F7 = Command/status
Status Register (Address 0x1F7):
7 6 5 4 3 2 1 0
BUSY READY FAULT SEEK DRQ CORR IDDEX ERROR
Error Register (Address 0x1F1): (check when ERROR==1)
7 6 5 4 3 2 1 0
BBK UNC MC IDNF MCR ABRT T0NF AMNF
BBK = Bad Block
UNC = Uncorrectable data error
MC = Media Changed
IDNF = ID mark Not Found
MCR = Media Change Requested
ABRT = Command aborted
T0NF = Track 0 Not Found
AMNF = Address Mark Not Found
Figure 36.5: The IDE Interface
- 드라이브가 Ready 상태가 될 대까지 기다린다. (Status 레지스터가 Ready가 될 때까지)
- Command 레지스터에 매개 변수를 쓴다. Command 레지스터에 섹터 수, 접근할 섹터의 LBA(논리 블록 주소) 및 드라이브 번호를 기록한다.
- I/O를 시작합니다. 이때 Command 레지스터에 읽기 쓰기를 실행한다.
- 데이터 전송 : 드라이브 STATUS가 READY, DRQ(데이터에 대한 드라이브 요청)이 될 때까지 기다립니다. 그런 뒤 데이터 포트에 데이터를 쓴단.
- Interrupt Handling : 글의 초반부에 인터럽트를 효율적으로 처리하는 방법에서 봤듯 여러 개의 인터럽트를 한 번에 처리할 수도 있고 각 섹터마다 인터럽트를 처리할 수도 있다.
- Error Handling : 작업을 한 뒤 STATUS 레지스터를 읽고 ERROR 비트가 켜진 상태라면 이를 처리한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
static int ide_wait_ready() {
while (((int r = inb(0x1f7)) & IDE_BSY) || !(r & IDE_DRDY))
; // loop until drive isn’t busy
// return -1 on error, or 0 otherwise
}
static void ide_start_request(struct buf *b) {
ide_wait_ready();
outb(0x3f6, 0); // generate interrupt
outb(0x1f2, 1); // how many sectors?
outb(0x1f3, b->sector & 0xff); // LBA goes here ...
outb(0x1f4, (b->sector >> 8) & 0xff); // ... and here
outb(0x1f5, (b->sector >> 16) & 0xff); // ... and here!
outb(0x1f6, 0xe0 | ((b->dev&1)<<4) | ((b->sector>>24)&0x0f));
if(b->flags & B_DIRTY){
outb(0x1f7, IDE_CMD_WRITE); // this is a WRITE
outsl(0x1f0, b->data, 512/4); // transfer data too!
} else {
outb(0x1f7, IDE_CMD_READ); // this is a READ (no data)
}
}
void ide_rw(struct buf *b) {
acquire(&ide_lock);
for (struct buf **pp = &ide_queue; *pp; pp=&(*pp)->qnext)
; // walk queue
*pp = b; // add request to end
if (ide_queue == b) // if q is empty
ide_start_request(b); // send req to disk
while ((b->flags & (B_VALID|B_DIRTY)) != B_VALID)
sleep(b, &ide_lock); // wait for completion
release(&ide_lock);
}
void ide_intr() {
struct buf *b;
acquire(&ide_lock);
if (!(b->flags & B_DIRTY) && ide_wait_ready() >= 0)
insl(0x1f0, b->data, 512/4); // if READ: get data
b->flags |= B_VALID;
b->flags &= ˜B_DIRTY;
wakeup(b); // wake waiting process
if ((ide_queue = b->qnext) != 0) // start next request
ide_start_request(ide_queue); // (if one exists)
release(&ide_lock);
}