ML - Lecture 20: Convolutional Neural Networks
시대가 점점 지나고 점점 neural network가 발전하게 되면서 deep learning의 중요성은 늘어나고 있다. 그중 특히 vision쪽에서의 유용함이 크다.
◼︎ Learning visual features
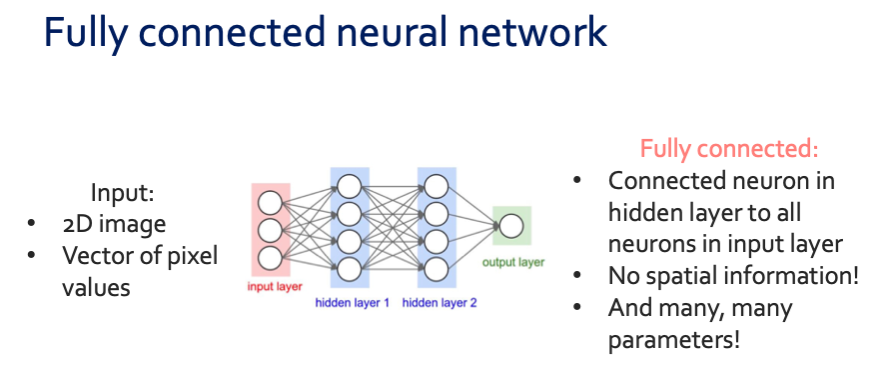
이렇게 하나하나 다 대응하면 너무 parameter가 많아지게 된다. 그래서 spatial structure라는 것을 이용하여 locally conneted하는 방식이 사용된다. 여러 patch를 이용해 부분적으로 parameter를 share한다고 생각하면 된다. 이는 convolution을 이용한다.
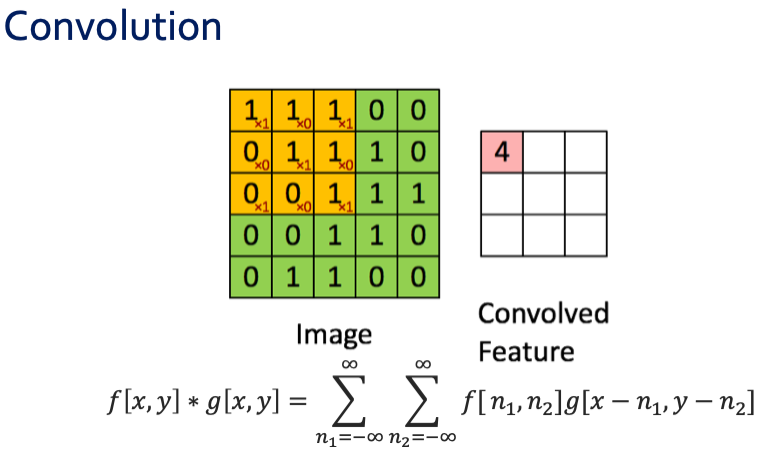
◼︎ Convolutional operation (1D examples)
이렇게 4가지의 convolution식의 변화를 통한 것들을 다 합쳐서 하나로 만들어낸다.
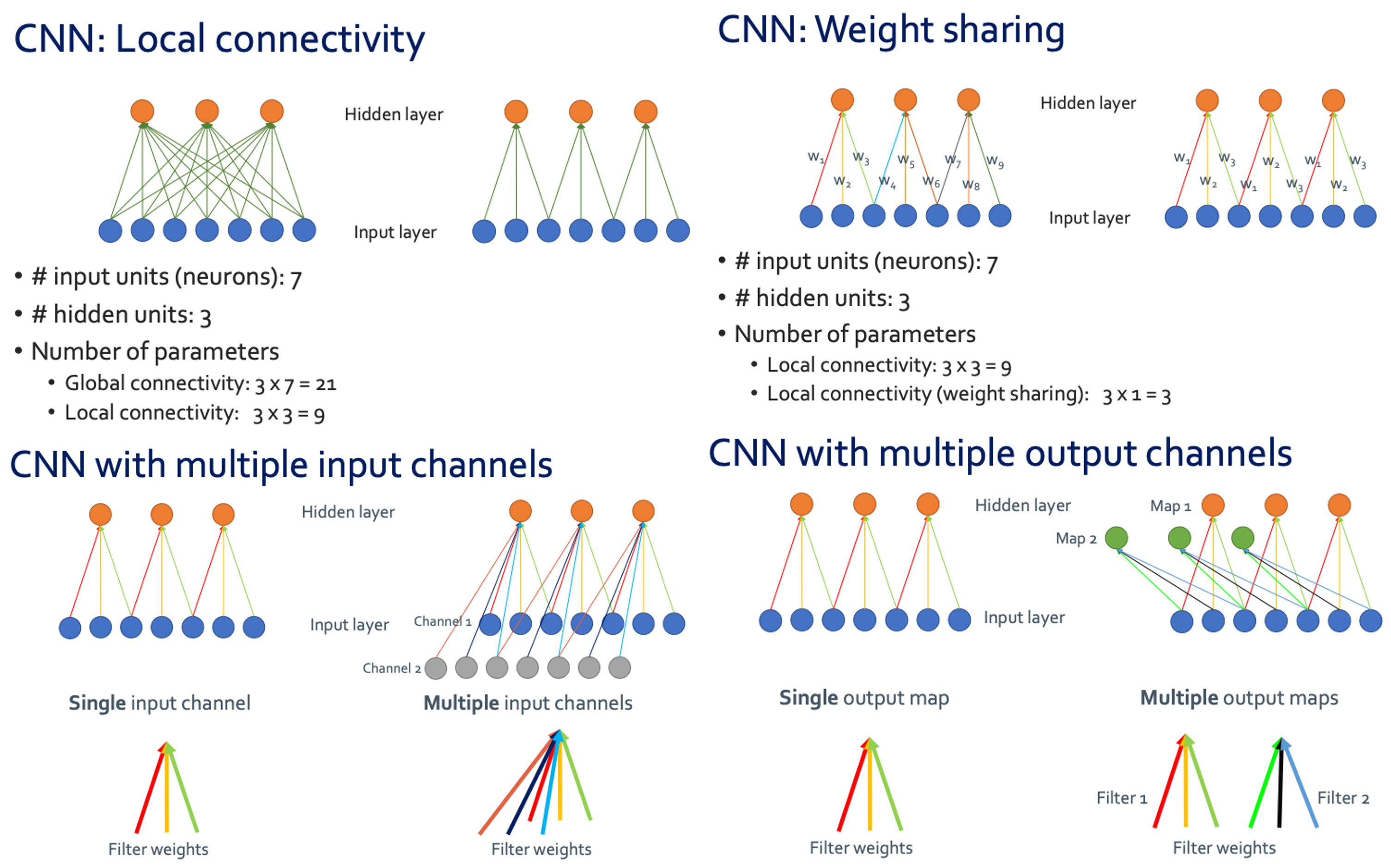
◼︎ Convolutional neural networks (CNN)
Fully일 때는 모든 숫자를 곱한 숫자만큼이 필요하지만 convolution layer를 사용하면 depth만 고정해주고 원하는 크기의 patch를 사용해 주면 된다.
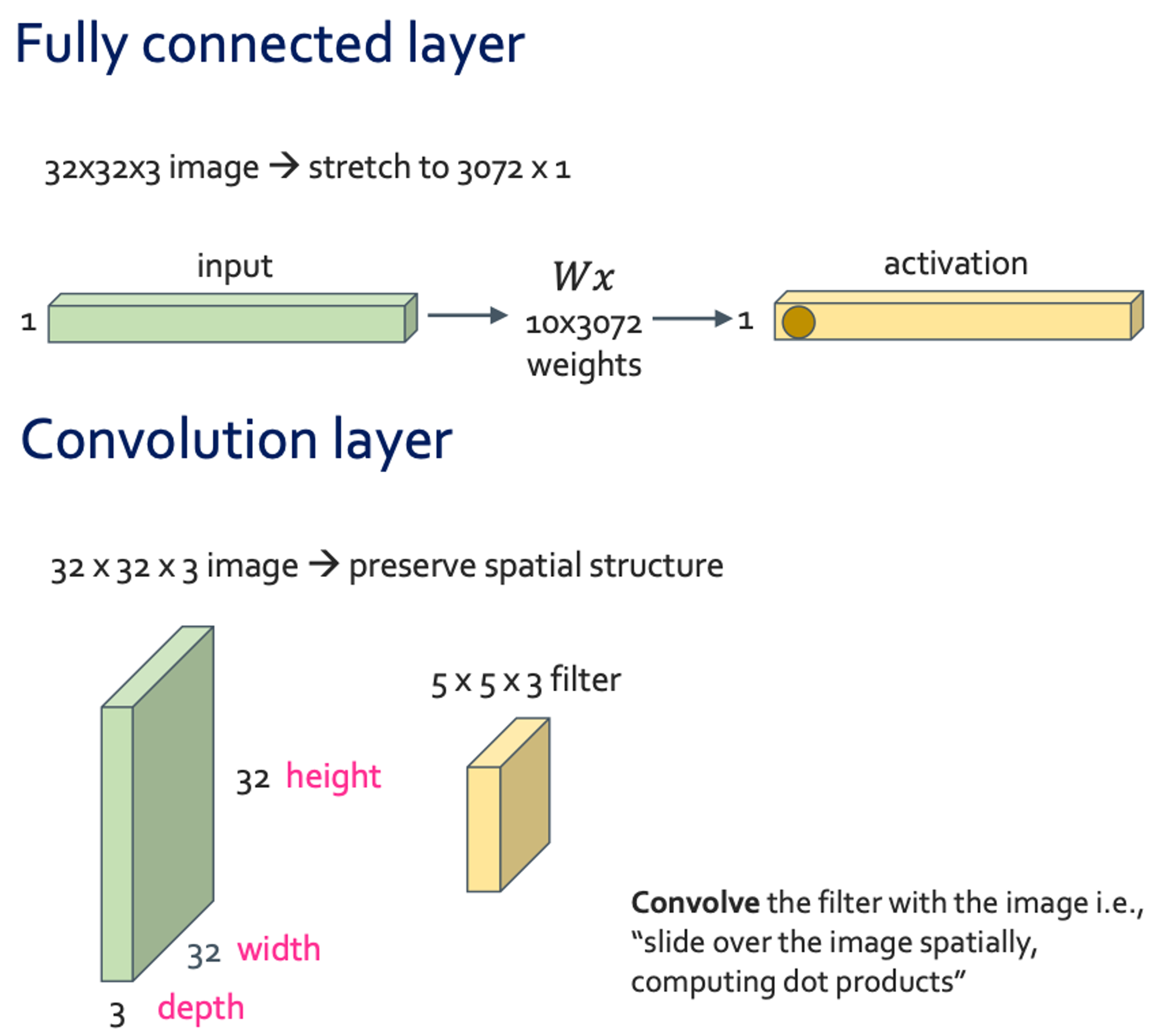
이렇게 convolution layer를 하나가 하니라 여러번씩 사용하면 ConvNet이 되는 것이다.
◼︎ Convolutional neural networks: Spatial dimensions
Output size = $\frac{\text{input size - filter size + (2*padding)}}{\text{Stride}}+1$
Number of parameters = filter size * depth + 1 (+1 for bias)
◼︎ Convolutional neural networks: POOL
Pooling은 representation을 더 작게 만드는 방식이다. 약간 압축 같은 것이다. 그래서 max pooling을 하면 그 스트라이트안에서 가장 큰 값을 대표로 가져가는 것이다. 풀링의 경우는 padding이 없고 stride가 filter size와 같게 된다. 그래서 공식은 다음과 같이 된다.
Output size = $\frac{\text{input size - filter size}}{\text{filter size}}+1 = \frac{\text{input size }}{\text{filter size}}$