ML - Lecture 10: Linear classifier - scaling up learning via SGD
◼︎ Stochastic gradient descent: Learning, one data point at a time
일단은 gradient ascent를 할 때 시간이 되게 오래 걸리게된다. 왜 그러는지 생각해 봤나?
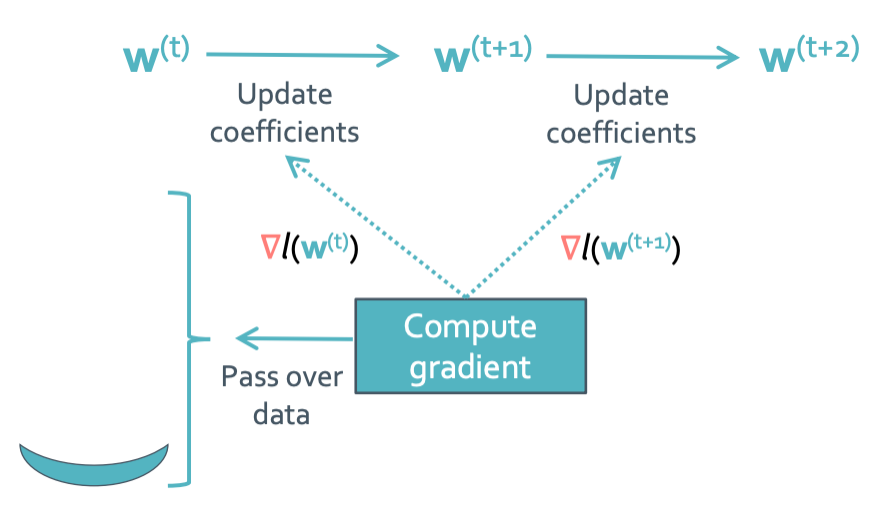
모든 update때 마다 모든 data를 다 체크해야하기 때문이다.

Expensive를 구하면 다음처럼 엄청 큰 수가 나오게 된다. 일단 뭘 줄여도 N이 너무 큰 수라서 연산량이 장난 아닌것이다.
Stochastic gradient ascent
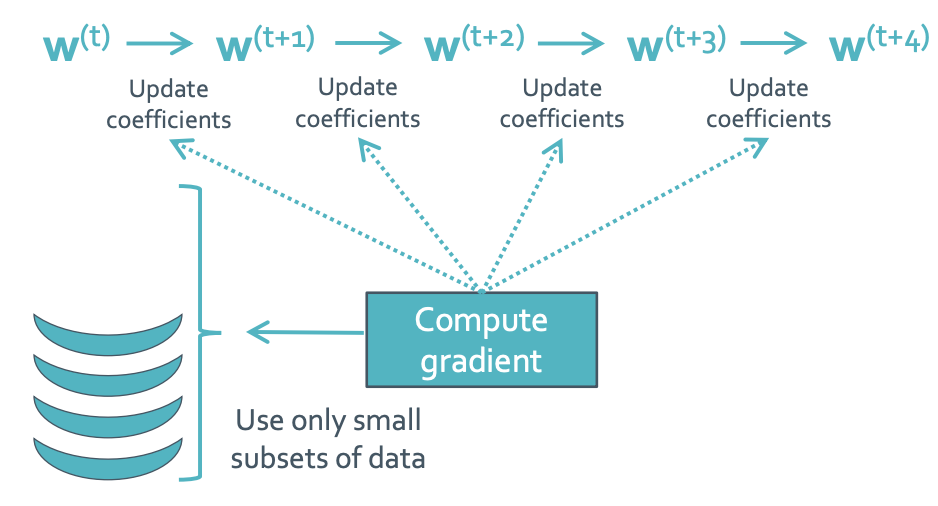
이렇게 하면 어떨까? test에 small subset만 사용하는 것이다. 이러면 연산량을 확 줄일 수 있을 것이다. 어짜피 update가 많이 되기도 해서 신뢰도 문제도 큰 상관이 없다. L2-regularization까지 고려하면 이렇게 된다.

N이 나눠지는 것을 조심해야한다.
Stochastic gradient ascent가 되는 이유가 뭘까? 일단 그냥 gradient는 “최적”의 올라가는 길을 찾아준다. 근데 여기서 생각해보면 되는게 모로가도 어쨌든 올라가면 되는거 아닌가? 최소한 내려가지만 않으면 언젠간 정상에 도달할것 아닌가? 이게 stochastic gradient ascent를 사용해도 되는 이유이다.
Convergence path
이것은 결국 stochastic gradient ascent를 하면 그냥 gradient ascent한 것에 수렴해지게 될 것이라는 뜻이다.
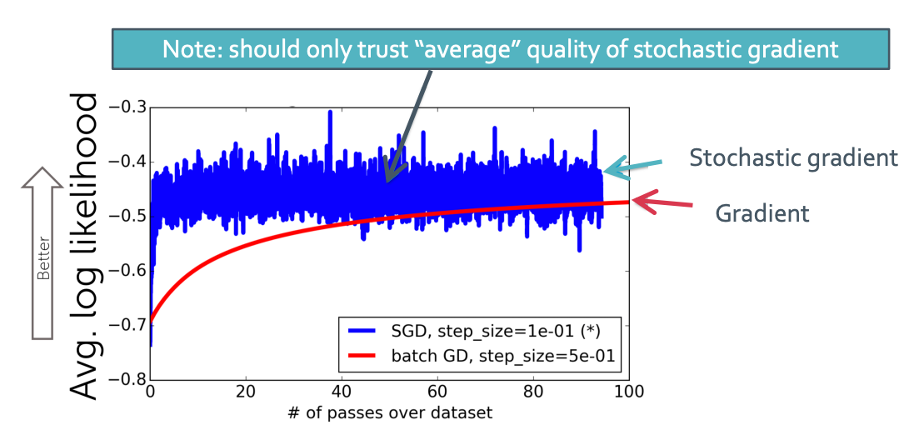
되게 noisy 한 그래프를 보이지만 data set을 많이 통과할 수록 정확해진다.
◼︎ Online learning: Fitting models from streaming data
Batch vs Online learning
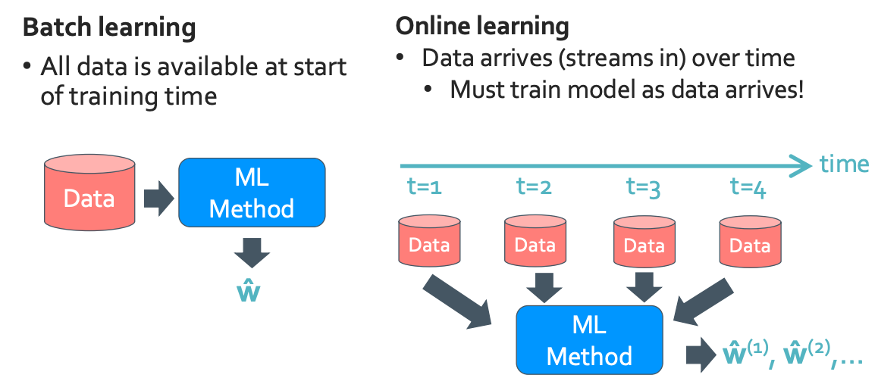
모델 수정이 되게 민감할것 같긴 하다. 일단 뭐가 됐든 당연 문제점도 존재한다.
Onine learning problem
매 time step마다 coefficients를 update하는 짓을 해야한다. 그래서 연산량이 정말 많은데 이것을 stochastic gradient ascent를 이용할 수 있다. 이렇게 연산량을 줄이고 정확도를 높이고 이렇게 하는게 계속 ML 수업을 들으면 하게 되는 것이다.
