CA - chapter 4 The Processor - Datapath and Control
앞에서는 성능과 명령어에 대하여 알아보았다. 이번 장에서는 하드웨어가 어떤식으로 구조가 돼있는지에 대해 배울 예정이다.
◼︎ 기본적인 RISC-V 구현
RISC-V의 핵심적인 부분은 3가지로 나뉜다.
- 메모리 참조 명령어(Memory-reference instruction): ld, sd
- 산술/논리 명령어(arithmetic-logical instruction): add, sub, and, or
- 조건부 분기 명령어(conditional branch instruction): beq
◼︎ 구현에 대한 개요
어떤 명령어를 선택하던 무조건 동일하게 해야하는 첫 과정이 있다.
First two steps
- 프로그램 카운터(PC)를 프로그램이 저장되어 있는 메모리로 보내서 메모리로부터 명령어를 가져오는(fetch) 것.
- 한 개 또는 2개의 레지스터를 읽는것.
이 이후 과정들은 명령어가 뭐든 거의 같은 행동을 한다. 보통 레지스터를 읽고 ALU를 사용하게 된다.
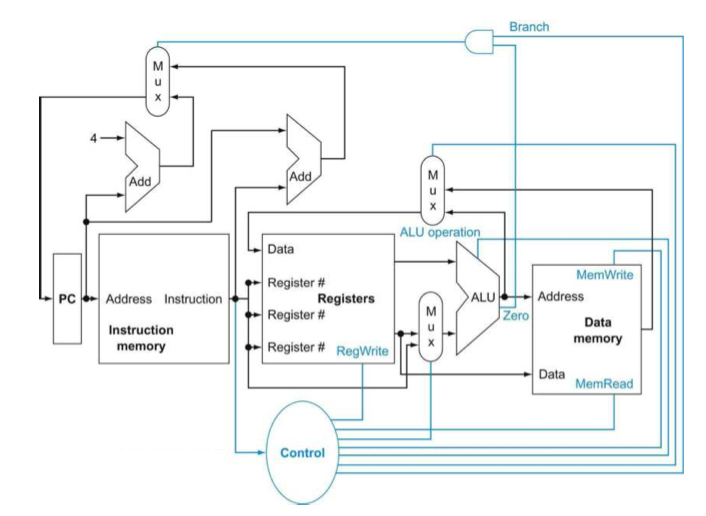
Abstract view of RISC-V
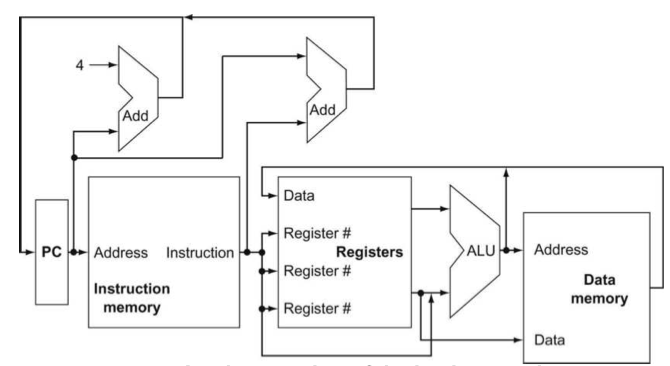
이것은 추상적인 RISC-V의 구조이다. 자세히 보면 input이 2개가 되는 지점들이 보일것이다. 이 구조가 추상적인 이유는 실제로는 이런 지점에 multiplexer가 포함되어야 하기 때문이다.
우선 모든 명령어의 실행은 PC를 사용하여 instruction memory에 명령어 주소를 보내는 것으로 시작된다. Instruction이 fetch되고 나면 register operand를 알 수 있게 된다. Operand를 보고 어떤 명령어를 실행해야하는지 알 수 있다. Arithmetic-logical instruction인 경우는 ALU의 결과를 레지스터에 쓴다. Load나 store이면 ALU 결과를 메모리 주소로 사용해서 레지스터 파일에 넣게된다. Branch의 경우는 ALU출력을 사용하여 다음 명령어 주소를 결정하게 되는데, 이 주소는 오른쪽 adder에서 PC+offset값이나 왼쪽 adder의 PC+4를 한 값이 된다.
Arithmetric-logical
Load & store
Branch
위에서 언급했듯 multiplexer와 그 multiplexer를 control하기 위한 controller가 필요하다.
◼︎ 클럭킹 방법론 (clocking methodology)
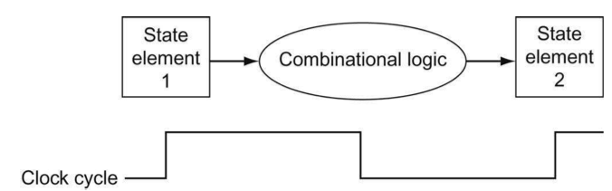
이것은 신호를 언제 읽고 쓰는지를 정의한다. 읽고 쓰기가 동시에 되면 어떤값이 과거값이고 현재값인지가 구분이 안되기 때문에 이를 용납하지 않는다.
Edge-triggered clocking
소자에 저장된 값은 clock edge에서만 바꿀 수 있는 방법이다.
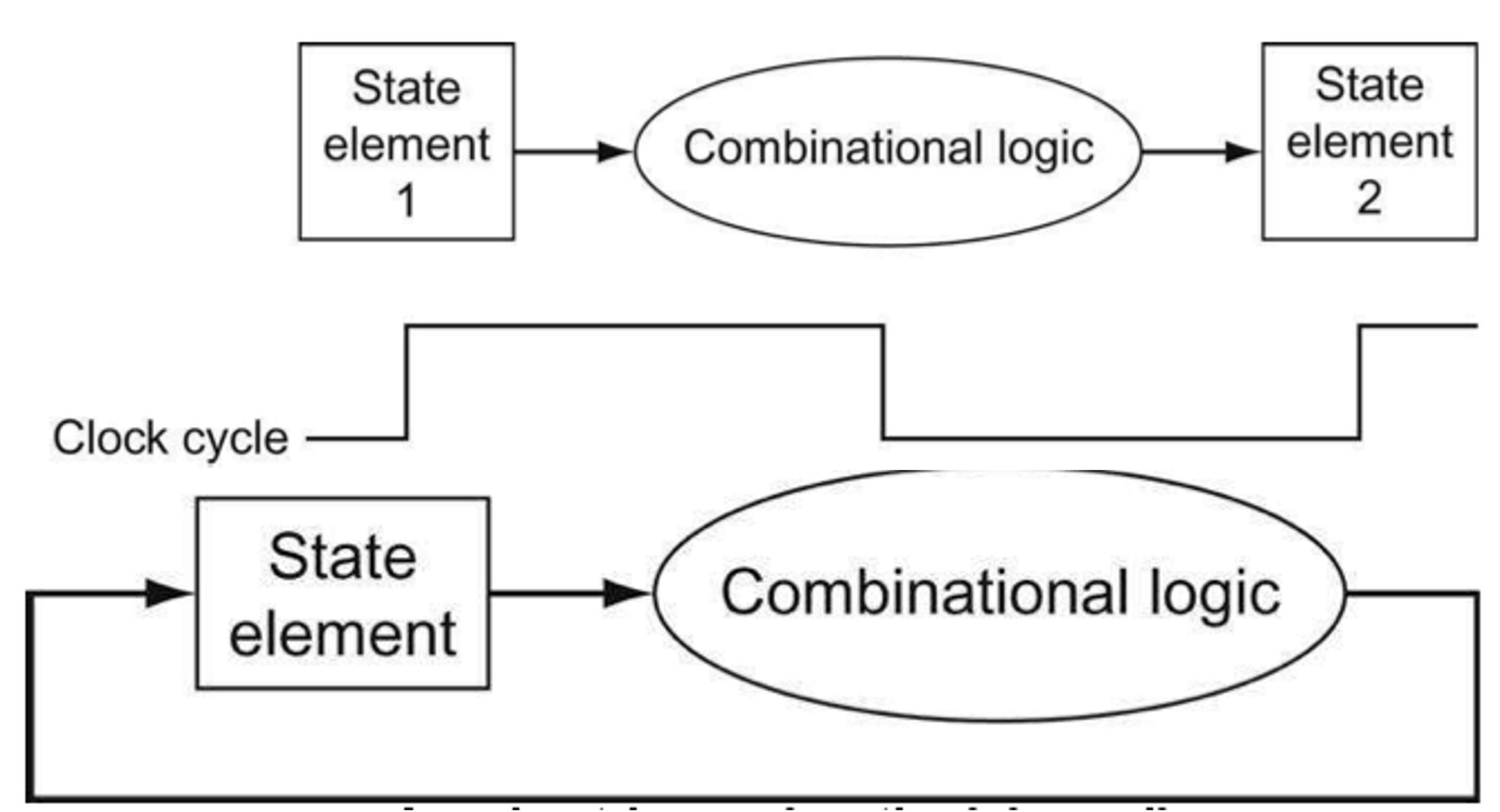
이 클락은 D-FF(Delay FlipFlop)에 의해 input과 output이 delay 되어 출력되는 것을 통해 구현된다.
◼︎ 데이터패스 만들기(Building a Datapath)
앞에서도 말했듯 어떤 명령어든 2개의 step은 항상 거친다고 하였다. PC에서 주소값 받아오고 insturtion memory로 input을 넣어 fetch 하는 것이었다.
Fetching instruction
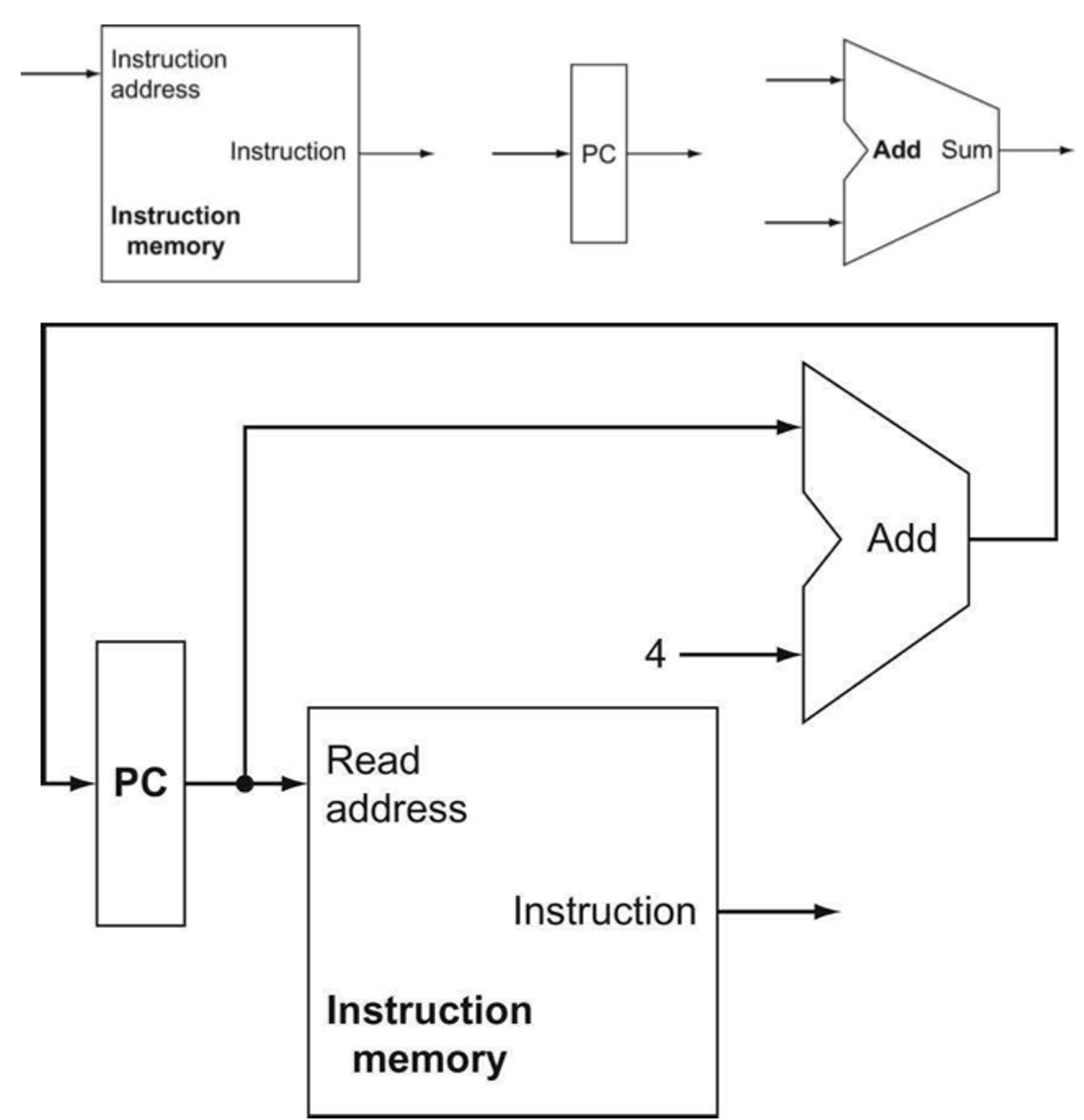
Fetching instruction은 이 3가지의 요소 instuction memroy, program counter, adder로 구현할 수 있다.
R-Format instructions
R-format instruction은 산술/논리 명령어fh add, sub, and, or 등을 담당한다고 했다. 이 형식은 모두 2개의 register를 모두 읽고 그 내용을 ALU에 넣어 연산하고 그 결과를 destination register에 쓴다. 즉, two data words read from the register file and one data word written into the register file.
RegWrite는 write operation을 control하기 위함이다. 읽는건 항상 하는거지만 write는 신호를 받아 clock edge에서 write모드로 다시 바꿔야 하기 때문이다.
Load and Store Operation
Intstruction은 ld x1, offset_value(x2)과 sd x1, offset_value(x2)의 구조를 가지고 있다. Store의 경우에는 data memory에 value를 write하고 load의 경우는 data memory에서 read한 값을 register file에 write한다.
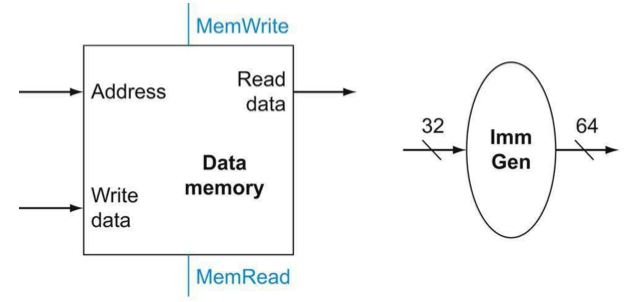
Immediate generation unit
Instruction의 binary code를 보면 immediate는 [11:0]으로 12bit이다. 그런데 우리가 쓰는 data는 현재 64bit이다. 그래서 bit를 늘려줘야 하는 것이다. 이것을 sign-extend라고 하고 Imm Gen에서 일어나는 일이다. 즉, Imm Gen에서는 32bit 전체를 받아 앞에 필요없는 opcode, func, rd, rs1을 다 제외하고 imm만 남기고 앞에는 sign-extend를 시켜 주는 것이다.
Branch implementation
beq의 경우는 two register 값을 받고 equality를 비교한다. 그리고 16-bit의 offset이 branch target address를 찾기 위해 계산된다.
Target address = (Sign extended offset << 1) + PC
여기서 예시를 들어보겠다.
1
beq x1, x2, 1
만약 현재 PC가 0x00400000 = 4,194,304₁₀이라고 하자. 그러면 어느 주소로 가야할까? 위의 공식을 이용하면 (1 « 1) = 2니까 4,194,304₁₀ + 2₁₀를 하면 뭐가 이상하지 않은가? 주소는 4비트씩 움직인다고 했는데…. 이건 앞에서 배운 immediate를 저장하는 방법에 힌트가 있다. 애초에 SB format에서는 2의 배수만 가능한 것이다. 그래서 [11:0]이 아닌 [12:1]로 저장된다는 것을 생각하면 된다. 이 예시가 가능해지려면 다음과 같이 돼야한다.
1
beq x1, x2, 2
이렇게 된다면 (2«1) = 4이기 때문에 4,194,304₁₀ + 4₁₀가 답인 것이다. 그래서 SB format이 [12:1] 형태로 저장돼 있다는 것은 halfword로 저장되어 있다고 생각하면 된다. 이게 바로 left shift 1 == $의 \times$2를 해주는 것이다. 이게 헷깔리는 이유는 I-format의 immediate 때문일 것인데, SB format의 branch offset과 I format의 offset은 다른거다.
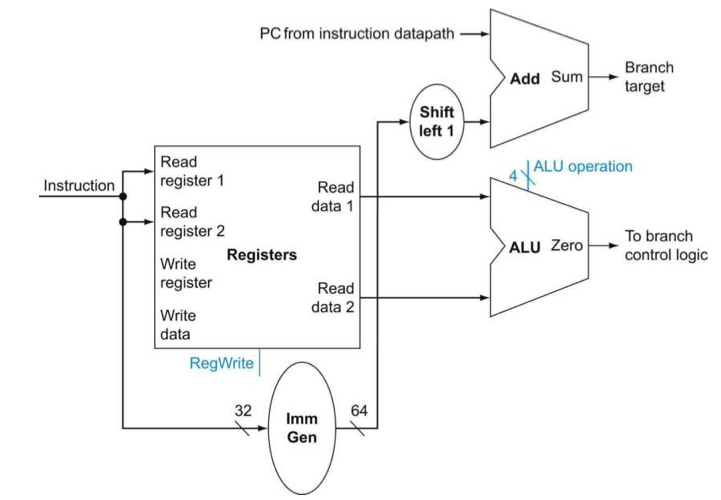
ALU 옆에 zero가 써진 이유는 branch instruction일 때 두 값을 비교하는 방식은 subtract 했을 때 0이냐 아니냐를 보는 것이기 때문이다. 만약 0이면 branch 돼야하니까 To branch control logic으로 나가고 나중에 볼 것이지만 control에서 나오는 branch 신호와 and가 되어 나중에 branch target address를 사용하도록 한다.
◼︎ 단순한 구현(A Simple Implementation Scheme)
제어 기능을 추가하여 구현한 data path를 볼 것이다.
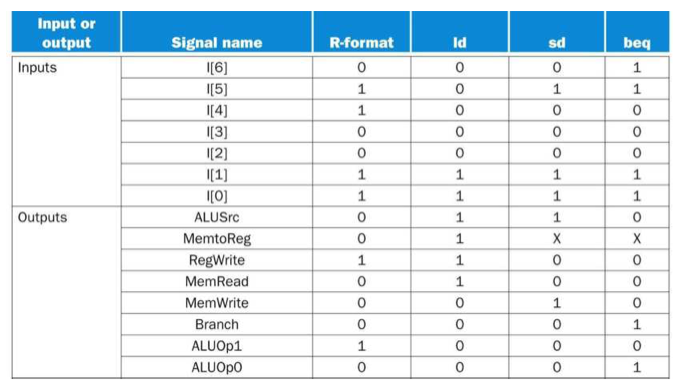
ALU 제어
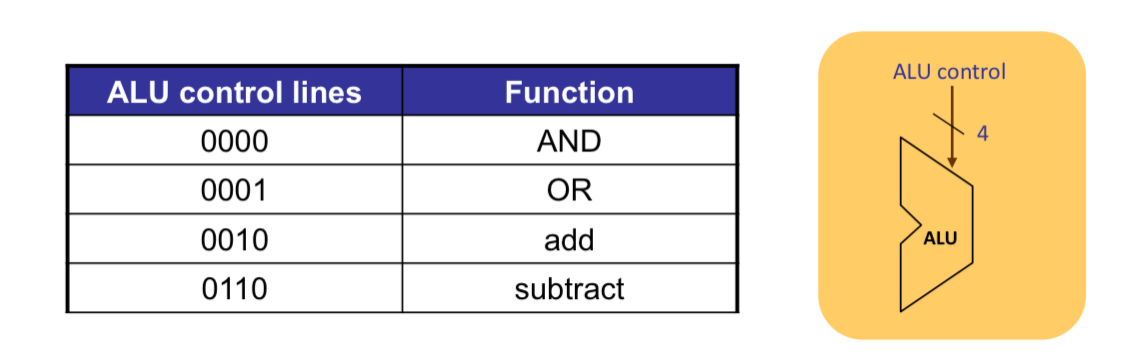
ALU의 경우 이 4가지에 control 신호에 의해 어떤 계산을 할 지 결정하게 된다.
- ld, sd: 메모리 주소 연산을 위해 add사용 - 00(ALUOp)
- R-type: 본인 타입에 맞는 연산 사용 - 10(ALUOp)
- beq: 비교를 위한 sub 사용 그리고 테스트 - 01(ALUOp)
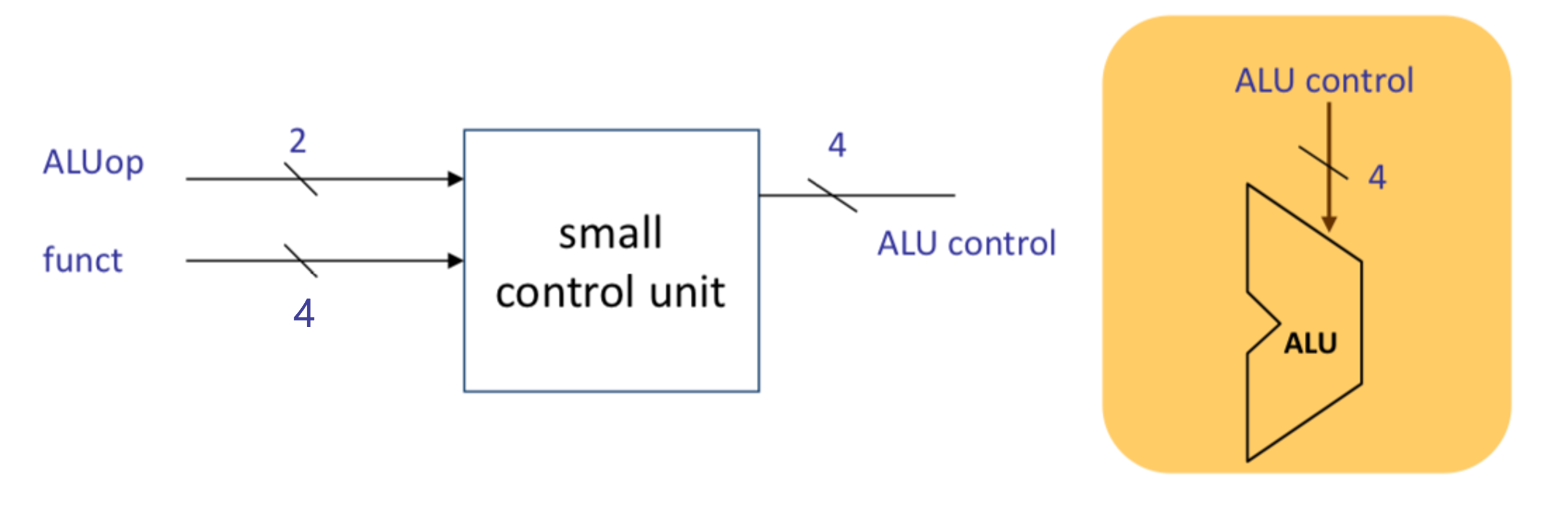
funct가 4bit인 이유는 다음 두 표를 보면 알 수 있다.
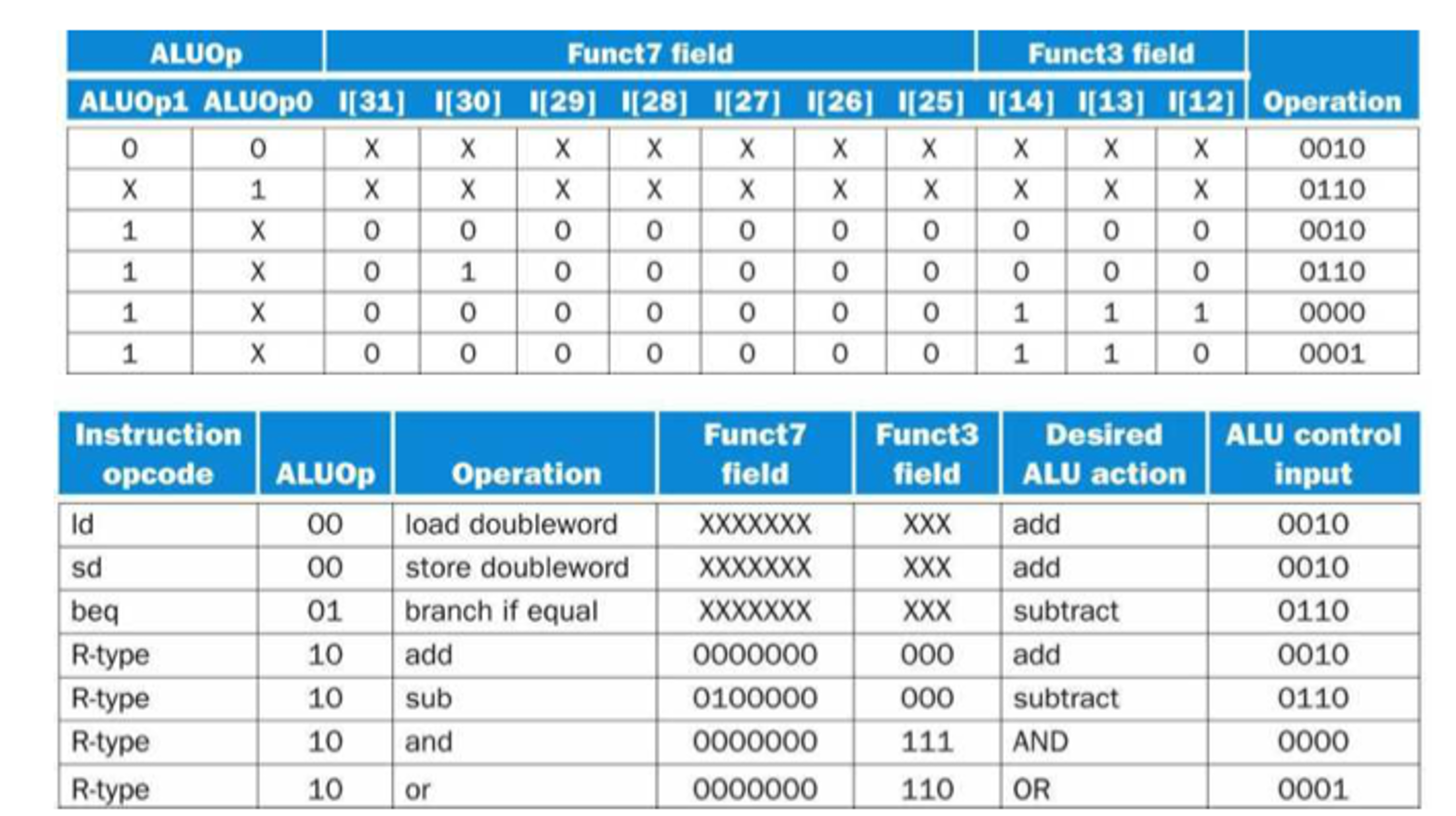
ld, sd, beq의 경우 funct가 필요없다. 그래서 x로 사용한 것이다. 그런데 R-type의 경우 funct가 있어야 어떤 연산을 할 것인지를 구별할 수 있게 된다. 그런데 여기서 보면 funct의 10bit를 모두 다 쓸 필요가 없다는 것이 보인다. 실제 차이를 구별하기 위해서는 오직 20, 14, 14, 12비트만 확인하면 어떤 명령어를 썼는지 알수 있다. 그래서 4bit의 funct가 들어가게 되는 것이다.
주 제어 유닛의 설계
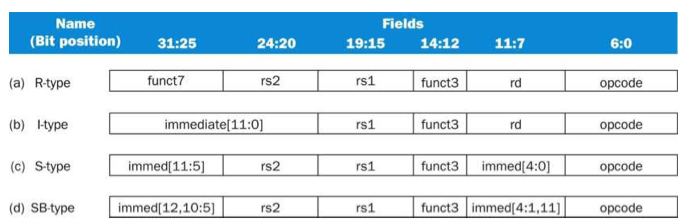
몇가지 설계의 기초가 되는 것들이 있다.
- opcode의 field는 항상 6:0이고 opcode에 따라 funct7,funct3를 확장 해야 할 수도 있다.
- R-type과 branch instruction의 첫 register(rs1)은 항상 19:15에 있다. (store/load에서는 base register)
- R-type과 branch instruction의 두 번째 register(rs2)은 항상 24:20에 있다. (store에서는 메모리에 저장될 register)
- Branch나 load/store의 immediate는 12bit이다.
- R-type과 load의 목적지 register(rd)는 항상 11:7이다.
Six control signals
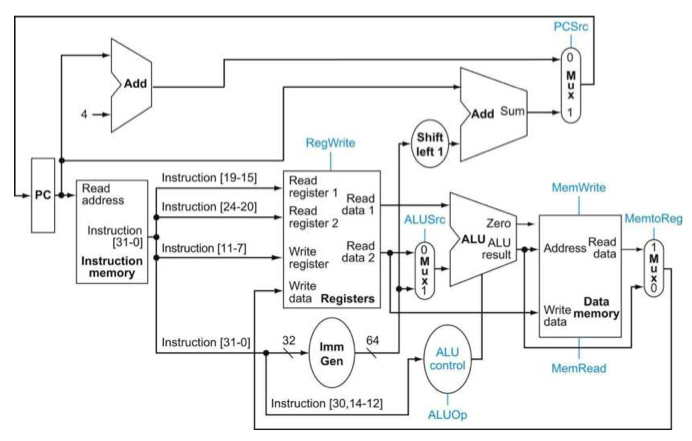
- RegWrite: 1이면 쓰기, 0이면 읽기
- ALUSrc: 1이면 imm, 0이면 rs2
- PCsrc: 1이면 branch, 0이면 PC+4
- MemRead: 1이면 memory 읽기, 0이면 아무것도 하지 않기
- MemWrite: 1이면 memory에 쓰기, 0이면 아무것도 하지 않기
- MemtoReg: 1이면 memroy에서 읽은 값 출력하기, 0이면 ALU의 계산값 출력하기
PCsrc가 맘에 되게 안든다. 그래서 이걸 AND를 이용해 수정해볼 것이다. 그래서 8 control signal로 만들어 볼 것이다.
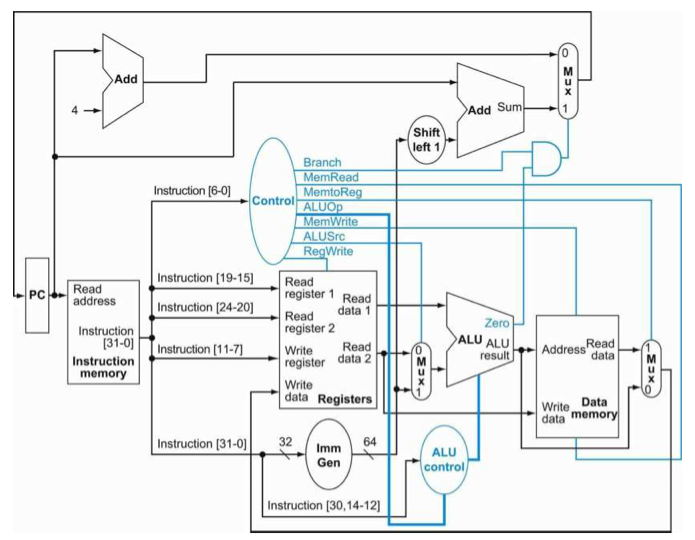
이렇게 PCsrc를 ALUOp와 Branch signal로 나누어주었다.
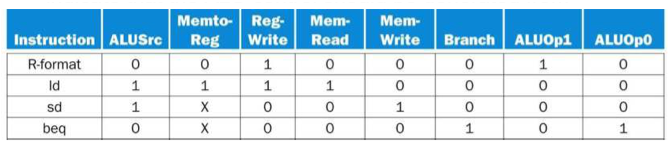
Four steps for R-type
- Instruction fetch & PC값 증가
- Register file에서 두 개 register 값 읽기(이 과정에서 control unit 계산)
- ALU operation
- ALU 계산 결과를 rd로 쓰기
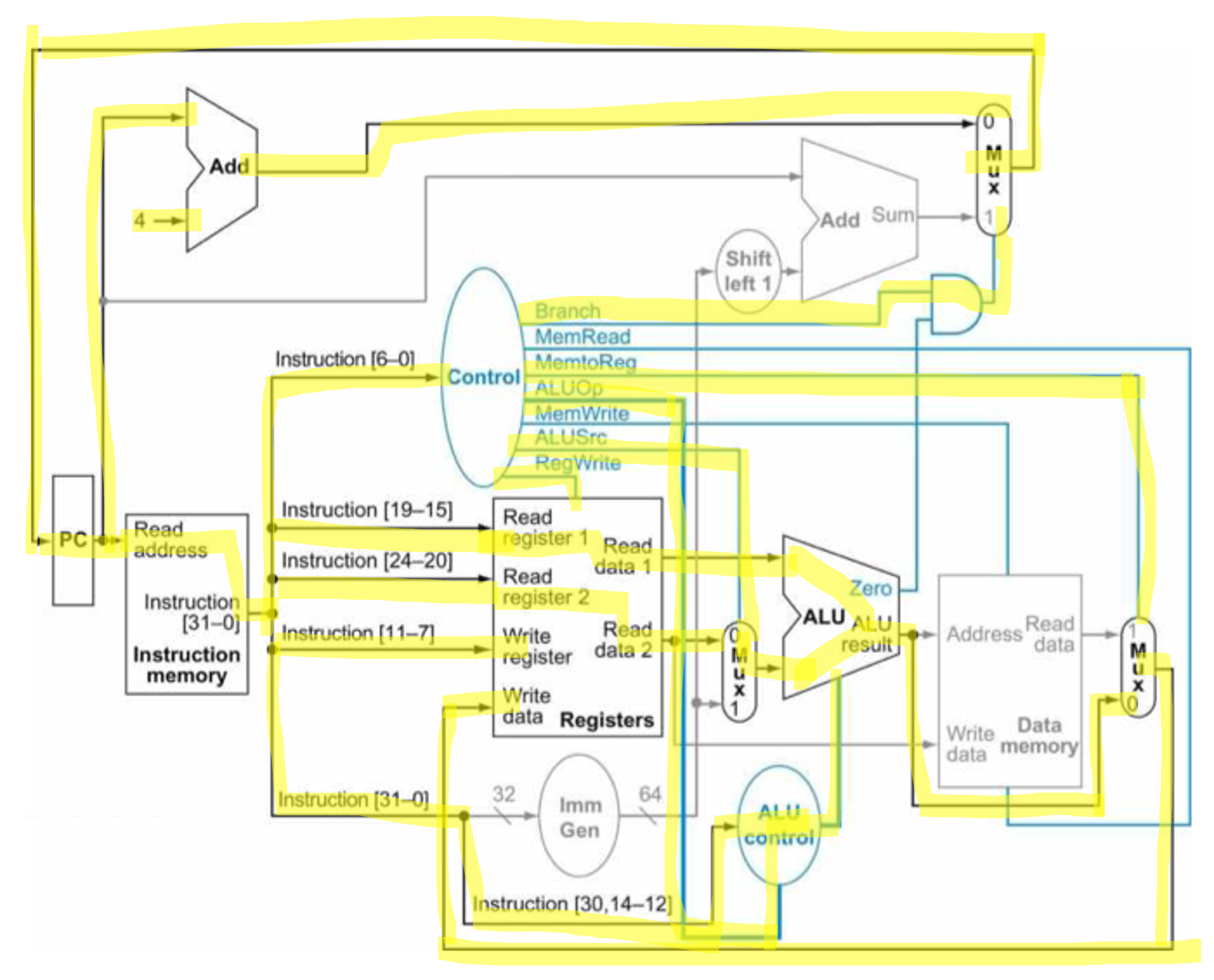
Steps for ld
- Instruction fetch & PC값 증가
- rs1 읽기
- rs1안에 있는 값 + sign-extended 12 bit(offset), add
- ALU에서 나온 결과값 data memory의 주소로 사용
- memory unit에서 나온 값을 rd로 쓰기
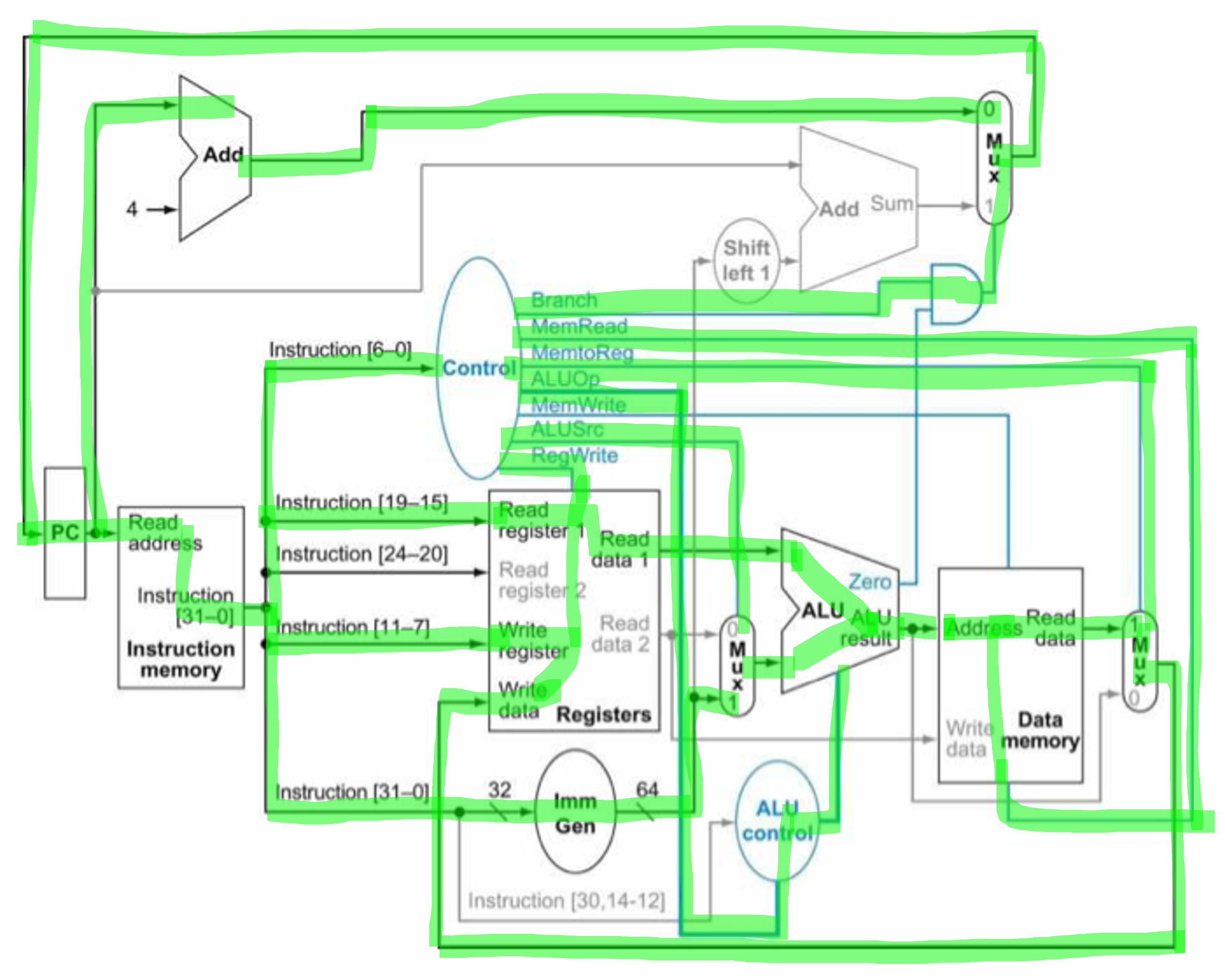
Steps for beq
- Instruction fetch & PC값 증가
- rs1, rs2 읽기
- ALU에서 sub하고 sign-extended 12bit를 « 1 해서 branch target address 구함
- ALU에서 0 나오면 PC + (sign-extended 12bit « 1)
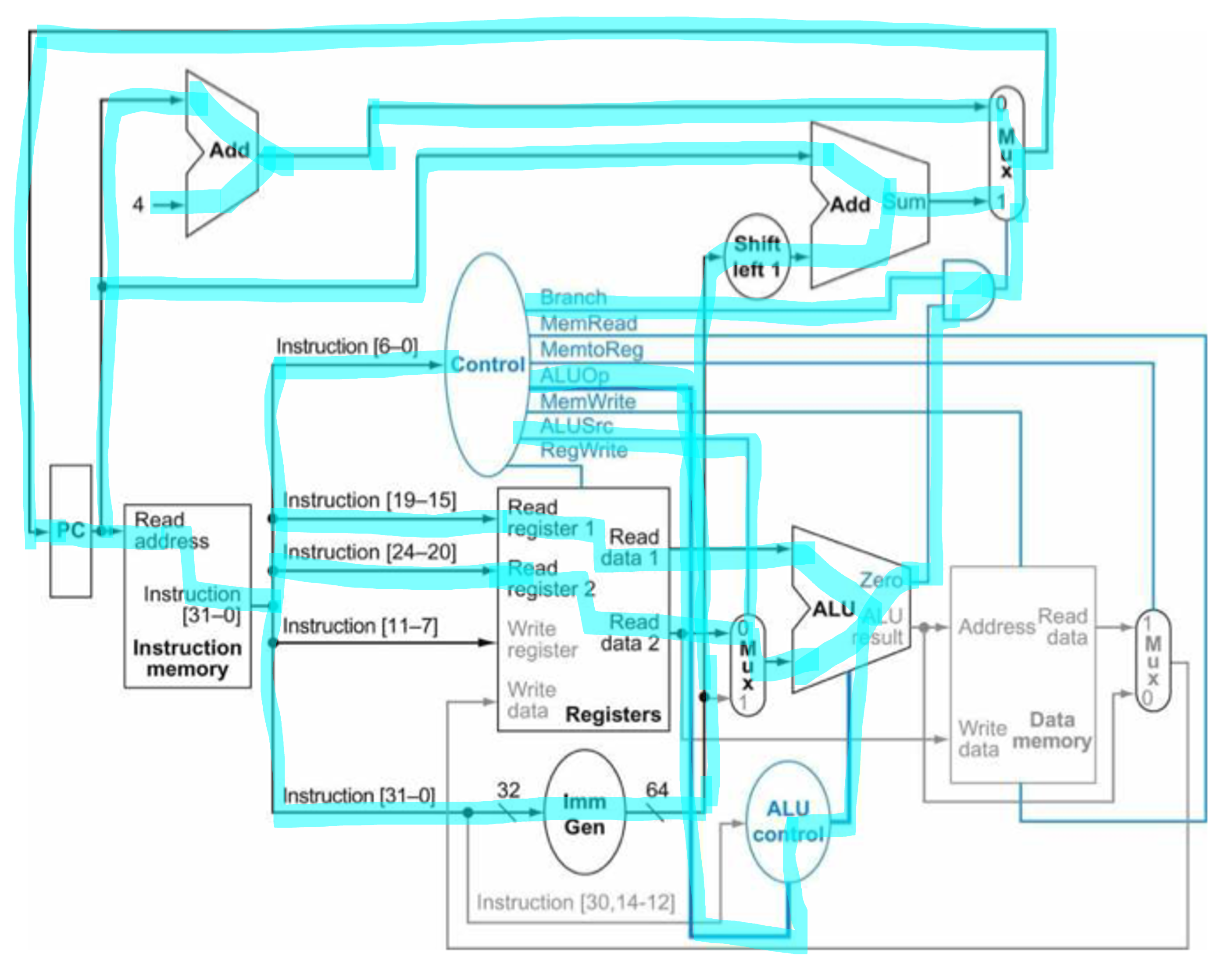
Single cycle
이렇게만 하면 single cycle을 완벽히 올바르게 작동시킬 수 있다. 하지만 비효율성 때문에 현대에는 이렇게 쓰이고 있지 않다.
여기까지가 중간 범위
◼︎ Overview of pipelining
여태까지 우리는 한 instruction의 실행이 끝나면 그 다음 instruction을 실행시키는 single cycle 방식으로 하였다. 하지만 이렇게 한 작업이 진행이 끝날때까지 기다리기만 하면 굉장히 비효율적이지 않을까?
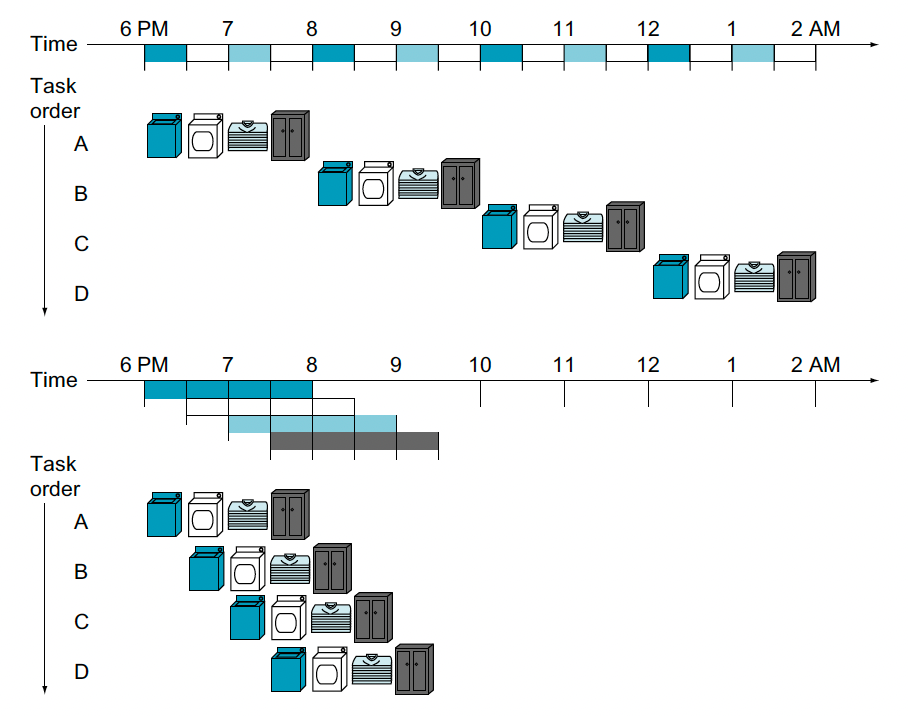
이 그림을 보면 집안일은 한다고 할때 모든 일이 끝날때 까지 기다리면 굉장히 오핸시간이 걸리게 된다. 하지만 아래의 그림을 보면 건조기가 돌아갈때 세탁기는 다 쓴거니 또 새로 돌릴수 있다. 약간 멀티태스킹한다는 것처럼 생각을 하면 시간이 굉장히 단축이 된다는 것을 볼 수 있다.
Steps in executing RISC-V
위에서 본것처럼 RISC-V가 실행되는 방식에도 step을 5가지로 나눌 수 있다.
- IF(i$): Fetch instruction, increment PC
- ID: Instruction, read register
- EX: memory-ref → address 연산, Arithmetic/logical Ops → 실행 연산
- MEM(D$): load → 메모리에서 data read, store → 메모리에 data write
- WB: Write data를 레지스터로
Example
| Instruction class | Instruction fetch | Register read | ALU operation | Data access | Register write | Total time |
|---|---|---|---|---|---|---|
| Load word (lw) | 200 ps | 100 ps | 200 ps | 200 ps | 100 ps | 800 ps |
| Store word (sw) | 200 ps | 100 ps | 200 ps | 200 ps | - | 700 ps |
| R-format (add, sub, and, or) | 200 ps | 100 ps | 200 ps | - | 100 ps | 600 ps |
| Branch (beq) | 200 ps | 100 ps | 200 ps | - | - | 500 ps |
실제로는 이런식으로 각각 다른 실행시간을 가지게 된다.
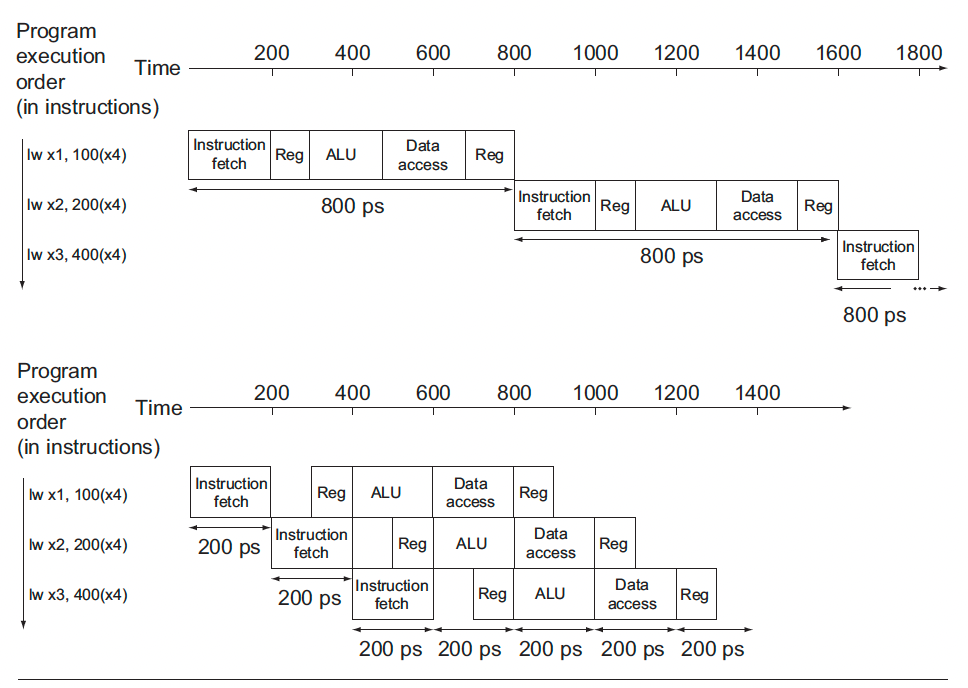
위의 표를 봤을 때 Total time은 명령어에 따라 달라진다는 것을 알 수 있지만 제일 큰 800ps를 기준으로 사용해야한다. 이렇듯 pipeline에서도 100ps처럼 짧게 걸리는 step이 있어도 최대 시간의 step인 200ps을 사용해야한다. 그래서 lw instruction을 3개를 실행한다고 하면 single cycle이면 2400ps가 걸리지만 pipeline을 사용하면 시간이 획기적으로 줄어서 1400ps만 걸린다는 것을 확인할 수 있다.
\[\text{Time between instructions}_{\text{pipelined}} = \frac{\text{Time between instructions}_{\text{nonpipelined}}}{\text{Number of pipe stages}}\]
위의 수식은 이상적인 공식이라서 nonpipelined가 위의 single cycle이랑 같은게 아니라 모든 단계의 step당 걸리는 시간이 같아야한다. 이런식으로 되면 $\frac{2400}{1400} \neq \frac{800}{200}$이다. 하지만 이것은 instruction의 숫자가 매우 작아서 그런데 많다고 가정해보자. 1,000,003 instructions를 사용한다고 하면 multi cycle을 이용할 때는 $1,000,000 \times 200ps + 1400ps = 200,001,400ps$이고 single cycle일 때는 $1,000,000 \times 800ps + 2,400ps = 800,002,400ps$이다.
[ \frac{800,!002,!400\ \text{ps}}{200,!001,!400\ \text{ps}} \approx \frac{800\ \text{ps}}{200\ \text{ps}} \approx 4.00 ]
그래서 실제로 실행시간 향상은 거의 이상적인 것과 일치하다. 이로 인해 알 수 있는 것은 pipelining은 instruction 숫자가 늘어날 수록 성능이 향상된다.
◼︎ Designing Instruction Sets for Pipelining
다음은 실제 RISC-V에서 구성되는 pipeline의 step(pipeline stage)이다.
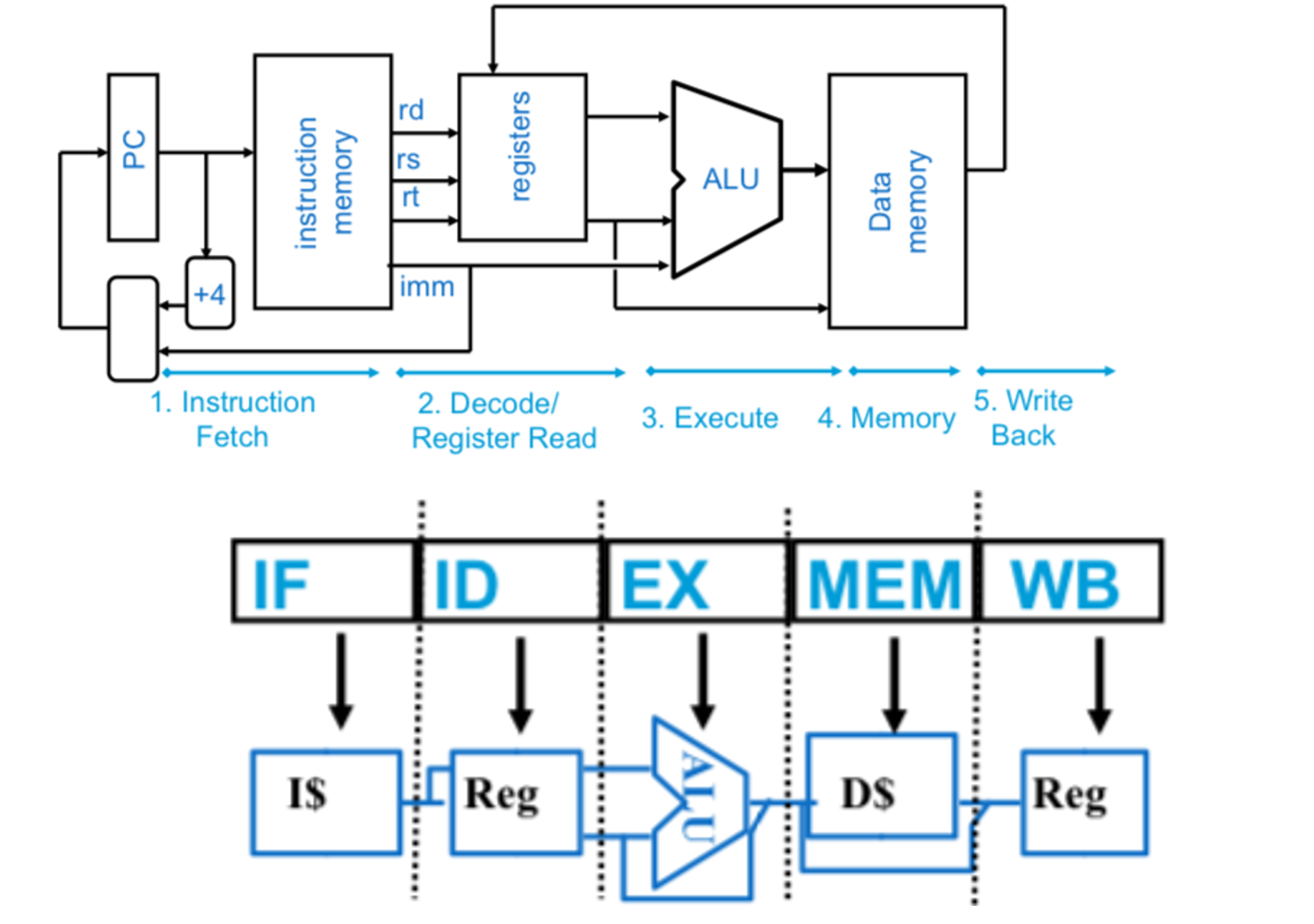
그리고 다음은 laod, add, store, sub, or의 instruction이 순서대로 진행될 때 pipeline의 graphic이다.
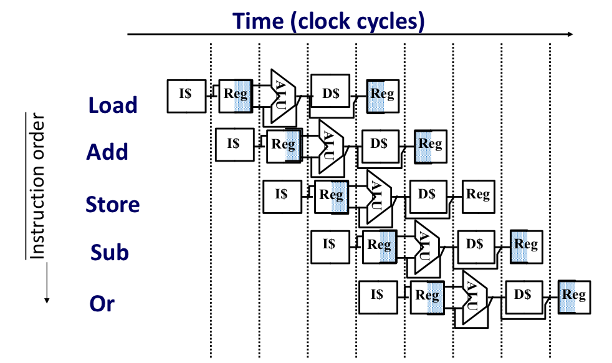
Add와 OR을 보면 Reg가 겹친 것 같지만 오른쪽에 색칠된 것은 read이고 왼쪽에 색칠된 것은 write이기 때문에 같은게 아니다.
Pipeline Hazard
어떠한 이유로 pipeline에서 바로 다음 clock에 다음 instruction이 나오지 않으면 hazard가 발생했다는 것이고 이는 stall(bubble)로 해결 할 수 있다. 즉, 그냥 instruction을 진행해도 될 때 까지 기다리는 것이고 그 사이 시간을 buuble이라고 하는 것이다.